 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Distillation for Decentralized Learning from Heterogeneous Clients
Paper and Code
Aug 18, 2020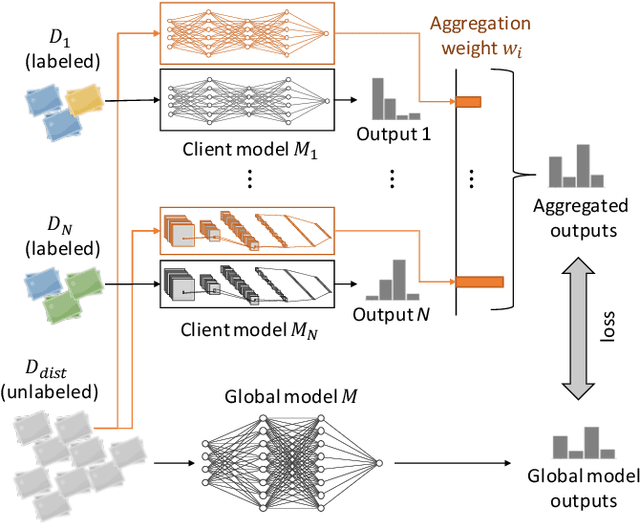
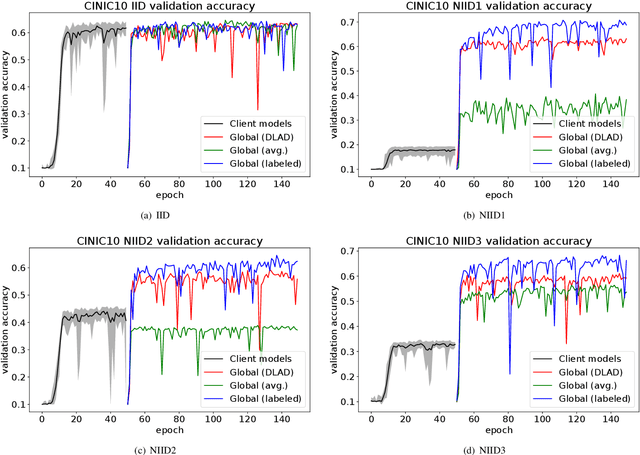
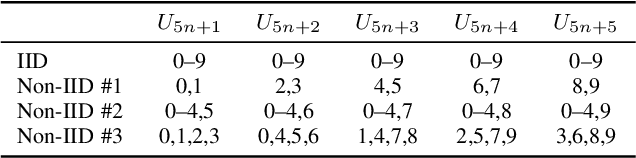

This paper addresses the problem of decentralized learning to achieve a high-performance global model by asking a group of clients to share local models pre-trained with their own data resources. We are particularly interested in a specific case where both the client model architectures and data distributions are diverse, which makes it nontrivial to adopt conventional approaches such as Federated Learning and network co-distillation. To this end, we propose a new decentralized learning method called Decentralized Learning via Adaptive Distillation (DLAD). Given a collection of client models and a large number of unlabeled distillation samples, the proposed DLAD 1) aggregates the outputs of the client models while adaptively emphasizing those with higher confidence in given distillation samples and 2) trains the global model to imitate the aggregated outputs. Our extensive experimental evaluation on multiple public datasets (MNIST, CIFAR-10, and CINIC-10) demonstrates the effectiveness of the proposed method.