 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEquivalent Classification Mapping for Weakly Supervised Temporal Action Localization
Paper and Code
Aug 18, 2020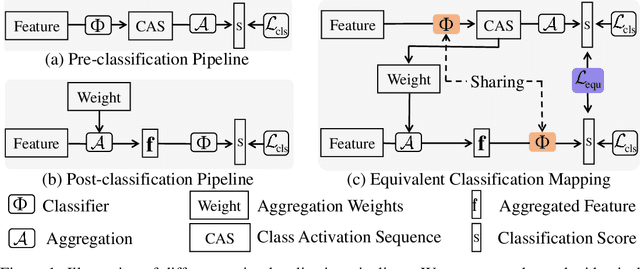
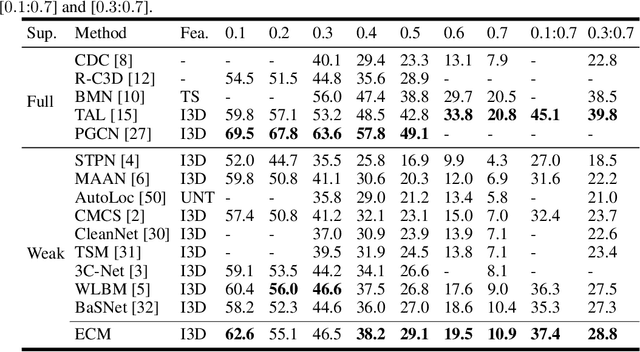
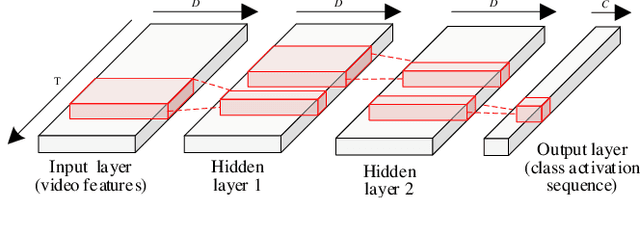
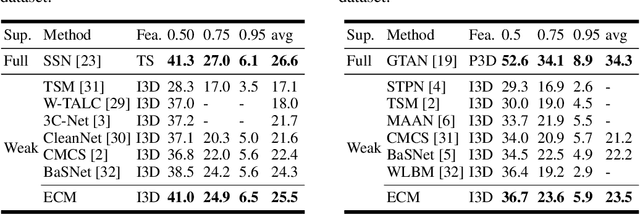
Weakly supervised temporal action localization is a newly emerging yet widely studied topic in recent years. The existing methods can be categorized into two localization-by-classification pipelines, i.e., the pre-classification pipeline and the post-classification pipeline. The pre-classification pipeline first performs classification on each video snippet and then aggregate the snippet-level classification scores to obtain the video-level classification score, while the post-classification pipeline aggregates the snippet-level features first and then predicts the video-level classification score based on the aggregated feature. Although the classifiers in these two pipelines are used in different ways, the role they play is exactly the same---to classify the given features to identify the corresponding action categories. To this end, an ideal classifier can make both pipelines work. This inspires us to simultaneously learn these two pipelines in a unified framework to obtain an effective classifier. Specifically, in the proposed learning framework, we implement two parallel network streams to model the two localization-by-classification pipelines simultaneously and make the two network streams share the same classifier, thus achieving the novel Equivalent Classification Mapping (ECM) mechanism. Considering that an ideal classifier would make the classification results of the two network streams be identical and make the frame-level classification scores obtained from the pre-classification pipeline and the feature aggregation weights in the post-classification pipeline be consistent, we further introduce an equivalent classification loss and an equivalent weight transition module to endow the proposed learning framework with such properties. Comprehensive experiments are carried on three benchmarks and the proposed ECM achieves superior performance over other state-of-the-art methods.