 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining Faster with Compressed Gradient
Paper and Code
Aug 13, 2020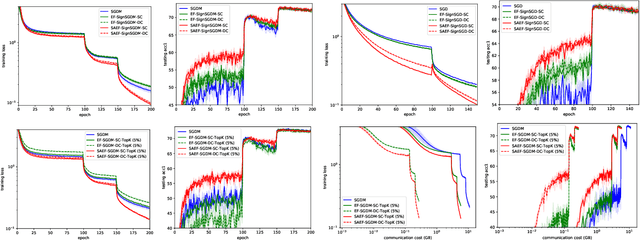
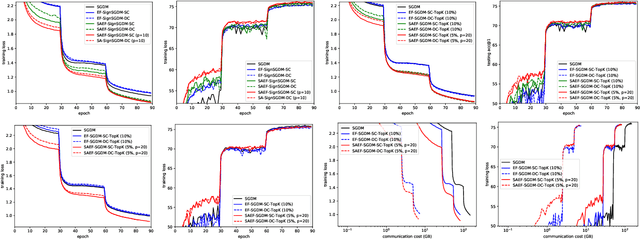
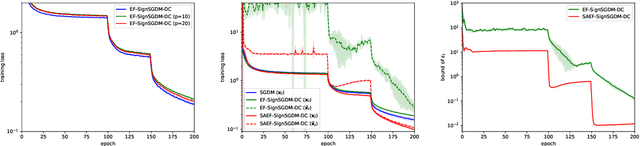
Although the distributed machine learning methods show the potential for the speed-up of training large deep neural networks, the communication cost has been the notorious bottleneck to constrain the performance. To address this challenge, the gradient compression based communication-efficient distributed learning methods were designed to reduce the communication cost, and more recently the local error feedback was incorporated to compensate for the performance loss. However, in this paper, we will show the "gradient mismatch" problem of the local error feedback in centralized distributed training and this issue can lead to degraded performance compared with full-precision training. To solve this critical problem, we propose two novel techniques: 1) step ahead; 2) error averaging. Both our theoretical and empirical results show that our new methods can alleviate the "gradient mismatch" problem. Experiments show that we can even train \textbf{faster with compressed gradient} than full-precision training \textbf{regarding training epochs}.