Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeApproaching Neural Chinese Word Segmentation as a Low-Resource Machine Translation Task
Paper and Code

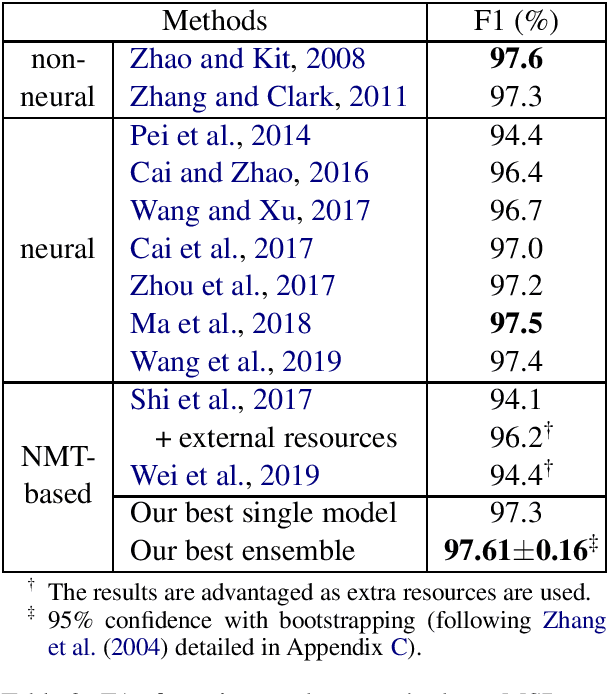
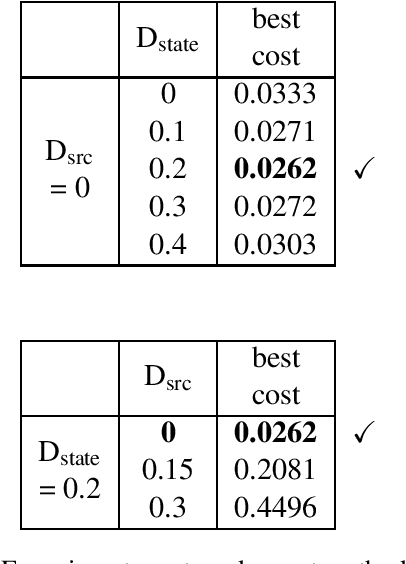
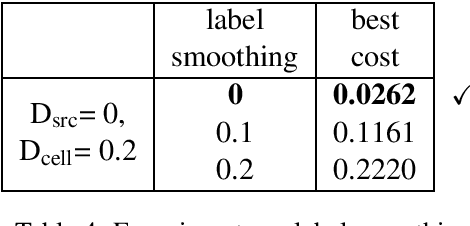
Supervised Chinese word segmentation has been widely approached as sequence labeling or sequence modeling. Recently, some researchers attempted to treat it as character-level translation, but there is still a performance gap between the translation-based approach and other methods. In this work, we apply the best practices from low-resource neural machine translation to Chinese word segmentation. We build encoder-decoder models with attention, and examine a series of techniques including regularization, data augmentation, objective weighting, transfer learning and ensembling. When benchmarked on MSR corpus under closed test condition without additional data, our method achieves 97.6% F1, which is on a par with the state of the art.
View paper on