 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntrinsic Certified Robustness of Bagging against Data Poisoning Attacks
Paper and Code
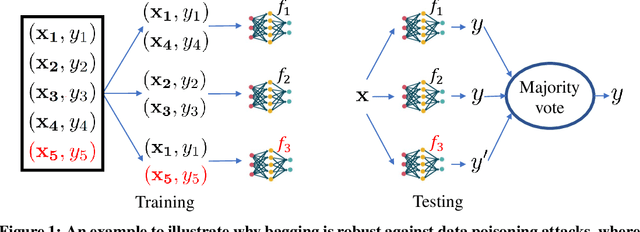
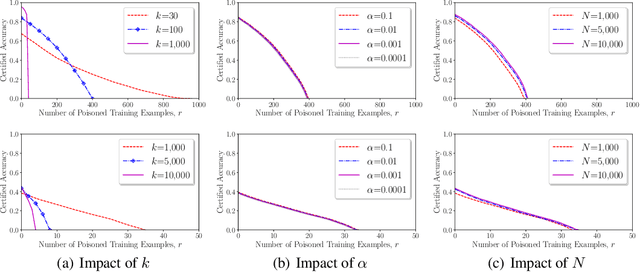
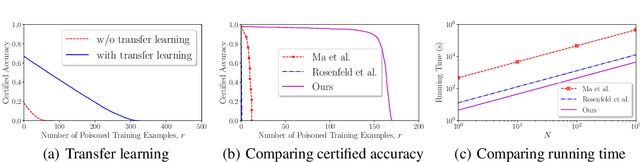
In a \emph{data poisoning attack}, an attacker modifies, deletes, and/or inserts some training examples to corrupt the learnt machine learning model. \emph{Bootstrap Aggregating (bagging)} is a well-known ensemble learning method, which trains multiple base models on random subsamples of a training dataset using a base learning algorithm and uses majority vote to predict labels of testing examples. We prove the intrinsic certified robustness of bagging against data poisoning attacks. Specifically, we show that bagging with an arbitrary base learning algorithm provably predicts the same label for a testing example when the number of modified, deleted, and/or inserted training examples is bounded by a threshold. Moreover, we show that our derived threshold is tight if no assumptions on the base learning algorithm are made. We empirically evaluate our method on MNIST and CIFAR10. For instance, our method can achieve a certified accuracy of $70.8\%$ on MNIST when arbitrarily modifying, deleting, and/or inserting 100 training examples.