 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFeature Space Augmentation for Long-Tailed Data
Paper and Code
Aug 09, 2020
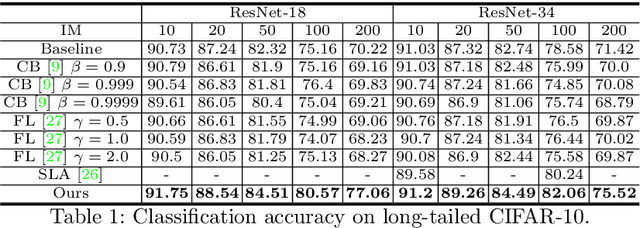
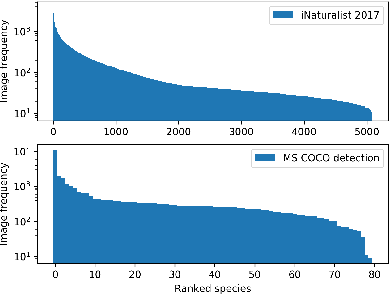
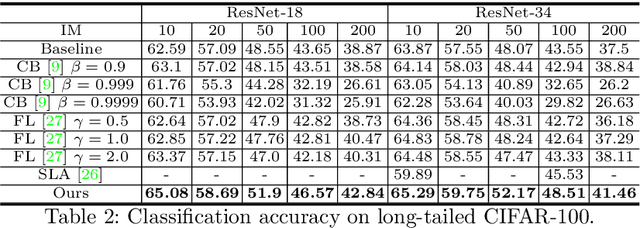
Real-world data often follow a long-tailed distribution as the frequency of each class is typically different. For example, a dataset can have a large number of under-represented classes and a few classes with more than sufficient data. However, a model to represent the dataset is usually expected to have reasonably homogeneous performances across classes. Introducing class-balanced loss and advanced methods on data re-sampling and augmentation are among the best practices to alleviate the data imbalance problem. However, the other part of the problem about the under-represented classes will have to rely on additional knowledge to recover the missing information. In this work, we present a novel approach to address the long-tailed problem by augmenting the under-represented classes in the feature space with the features learned from the classes with ample samples. In particular, we decompose the features of each class into a class-generic component and a class-specific component using class activation maps. Novel samples of under-represented classes are then generated on the fly during training stages by fusing the class-specific features from the under-represented classes with the class-generic features from confusing classes. Our results on different datasets such as iNaturalist, ImageNet-LT, Places-LT and a long-tailed version of CIFAR have shown the state of the art performances.