 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFederated Transfer Learning with Dynamic Gradient Aggregation
Paper and Code
Aug 06, 2020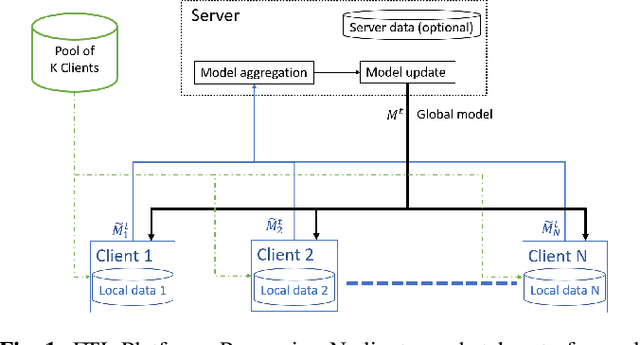
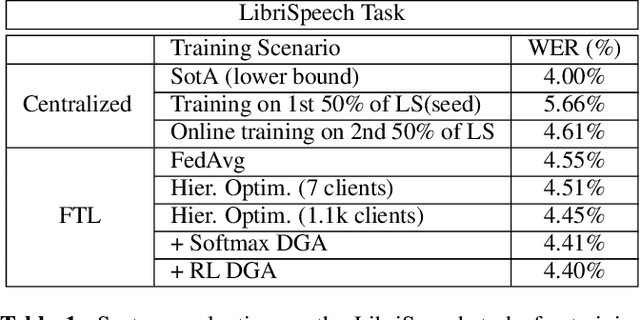
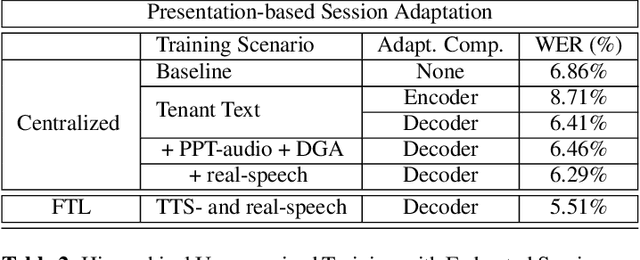
In this paper, a Federated Learning (FL) simulation platform is introduced. The target scenario is Acoustic Model training based on this platform. To our knowledge, this is the first attempt to apply FL techniques to Speech Recognition tasks due to the inherent complexity. The proposed FL platform can support different tasks based on the adopted modular design. As part of the platform, a novel hierarchical optimization scheme and two gradient aggregation methods are proposed, leading to almost an order of magnitude improvement in training convergence speed compared to other distributed or FL training algorithms like BMUF and FedAvg. The hierarchical optimization offers additional flexibility in the training pipeline besides the enhanced convergence speed. On top of the hierarchical optimization, a dynamic gradient aggregation algorithm is proposed, based on a data-driven weight inference. This aggregation algorithm acts as a regularizer of the gradient quality. Finally, an unsupervised training pipeline tailored to FL is presented as a separate training scenario. The experimental validation of the proposed system is based on two tasks: first, the LibriSpeech task showing a speed-up of 7x and 6% Word Error Rate reduction (WERR) compared to the baseline results. The second task is based on session adaptation providing an improvement of 20% WERR over a competitive production-ready LAS model. The proposed Federated Learning system is shown to outperform the golden standard of distributed training in both convergence speed and overall model performance.