 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultilingual Translation with Extensible Multilingual Pretraining and Finetuning
Paper and Code
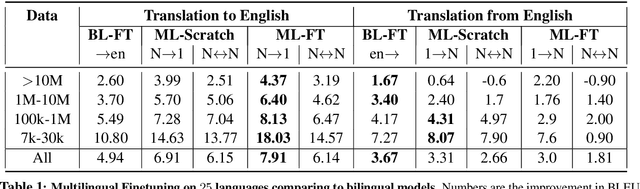
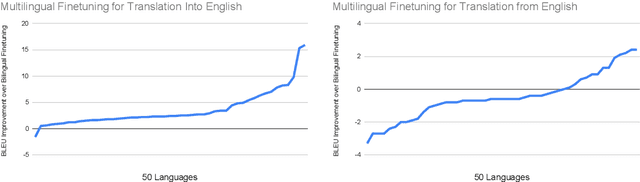
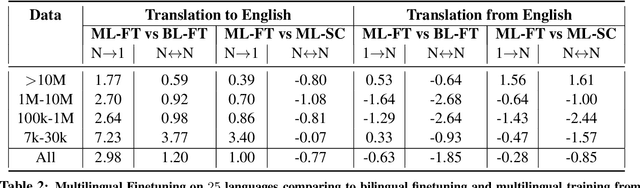
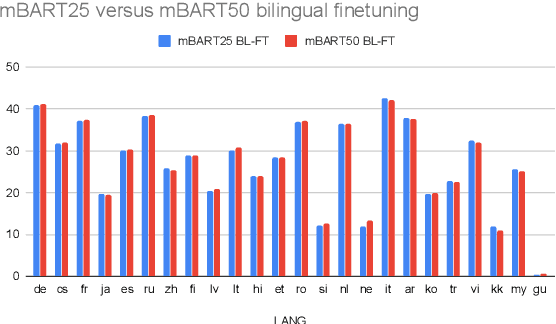
Recent work demonstrates the potential of multilingual pretraining of creating one model that can be used for various tasks in different languages. Previous work in multilingual pretraining has demonstrated that machine translation systems can be created by finetuning on bitext. In this work, we show that multilingual translation models can be created through multilingual finetuning. Instead of finetuning on one direction, a pretrained model is finetuned on many directions at the same time. Compared to multilingual models trained from scratch, starting from pretrained models incorporates the benefits of large quantities of unlabeled monolingual data, which is particularly important for low resource languages where bitext is not available. We demonstrate that pretrained models can be extended to incorporate additional languages without loss of performance. We double the number of languages in mBART to support multilingual machine translation models of 50 languages. Finally, we create the ML50 benchmark, covering low, mid, and high resource languages, to facilitate reproducible research by standardizing training and evaluation data. On ML50, we demonstrate that multilingual finetuning improves on average 1 BLEU over the strongest baselines (being either multilingual from scratch or bilingual finetuning) while improving 9.3 BLEU on average over bilingual baselines from scratch.