 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploiting Cross-Lingual Knowledge in Unsupervised Acoustic Modeling for Low-Resource Languages
Paper and Code
Jul 29, 2020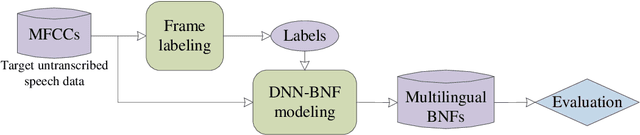
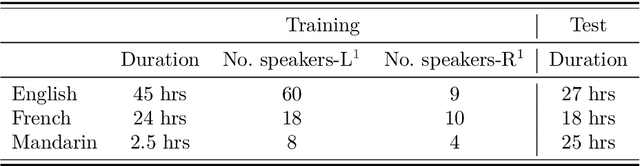
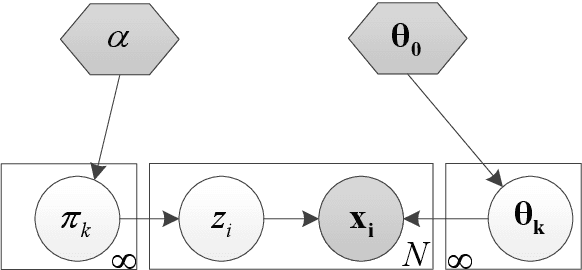

(Short version of Abstract) This thesis describes an investigation on unsupervised acoustic modeling (UAM) for automatic speech recognition (ASR) in the zero-resource scenario, where only untranscribed speech data is assumed to be available. UAM is not only important in addressing the general problem of data scarcity in ASR technology development but also essential to many non-mainstream applications, for examples, language protection, language acquisition and pathological speech assessment. The present study is focused on two research problems. The first problem concerns unsupervised discovery of basic (subword level) speech units in a given language. Under the zero-resource condition, the speech units could be inferred only from the acoustic signals, without requiring or involving any linguistic direction and/or constraints. The second problem is referred to as unsupervised subword modeling. In its essence a frame-level feature representation needs to be learned from untranscribed speech. The learned feature representation is the basis of subword unit discovery. It is desired to be linguistically discriminative and robust to non-linguistic factors. Particularly extensive use of cross-lingual knowledge in subword unit discovery and modeling is a focus of this research.