Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModel Size Reduction Using Frequency Based Double Hashing for Recommender Systems
Paper and Code
Jul 28, 2020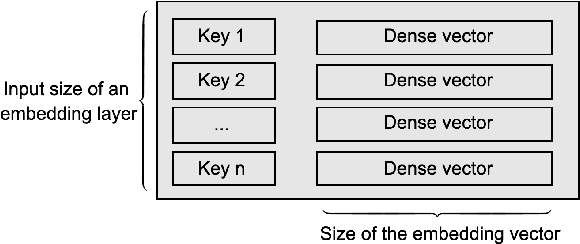
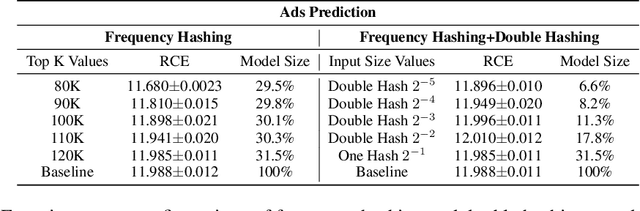
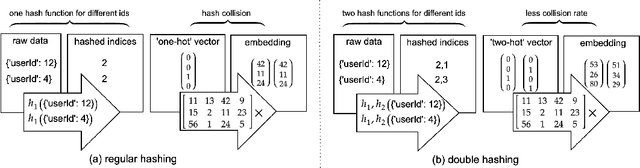
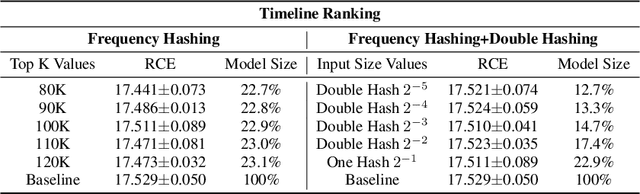
Deep Neural Networks (DNNs) with sparse input features have been widely used in recommender systems in industry. These models have large memory requirements and need a huge amount of training data. The large model size usually entails a cost, in the range of millions of dollars, for storage and communication with the inference services. In this paper, we propose a hybrid hashing method to combine frequency hashing and double hashing techniques for model size reduction, without compromising performance. We evaluate the proposed models on two product surfaces. In both cases, experiment results demonstrated that we can reduce the model size by around 90 % while keeping the performance on par with the original baselines.
* Paper is accepted to RecSys 2020
View paper on