 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast-Convergent Federated Learning
Paper and Code
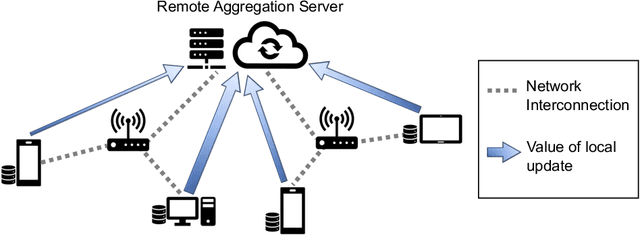
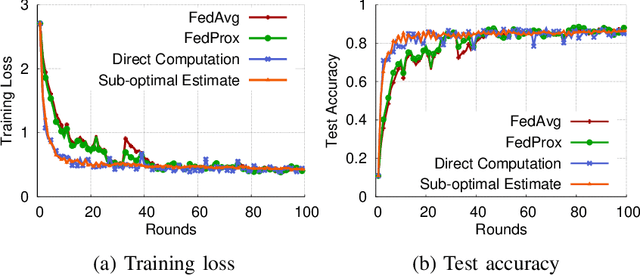
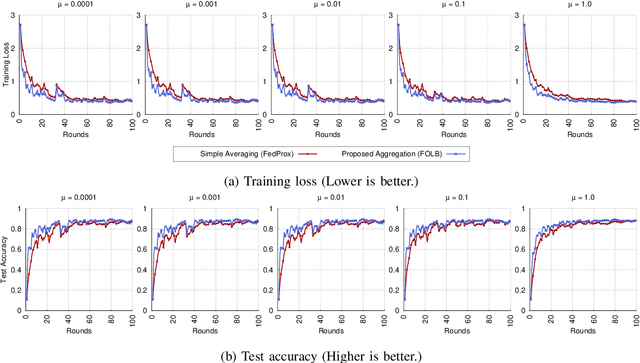
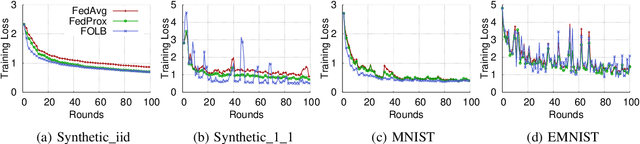
Federated learning has emerged recently as a promising solution for distributing machine learning tasks through modern networks of mobile devices. Recent studies have obtained lower bounds on the expected decrease in model loss that is achieved through each round of federated learning. However, convergence generally requires a large number of communication rounds, which induces delay in model training and is costly in terms of network resources. In this paper, we propose a fast-convergent federated learning algorithm, called FOLB, which obtains significant improvements in convergence speed through intelligent sampling of devices in each round of model training. We first theoretically characterize a lower bound on improvement that can be obtained in each round if devices are selected according to the expected improvement their local models will provide to the current global model. Then, we show that FOLB obtains this bound through uniform sampling by weighting device updates according to their gradient information. FOLB is able to handle both communication and computation heterogeneity of devices by adapting the aggregations according to estimates of device's capabilities of contributing to the updates. We evaluate FOLB in comparison with existing federated learning algorithms and experimentally show its improvement in training loss and test accuracy across various machine learning tasks and datasets.