 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust and Generalizable Visual Representation Learning via Random Convolutions
Paper and Code
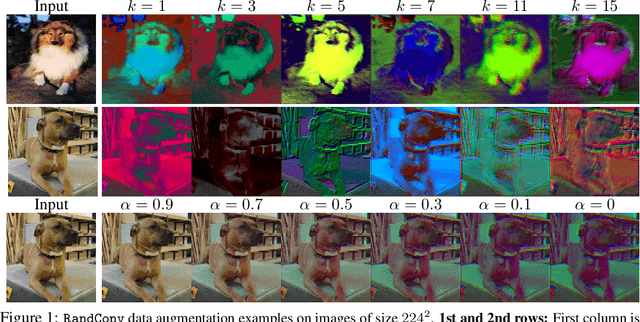
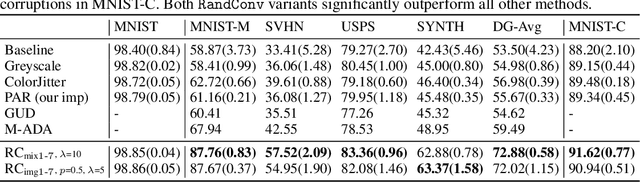
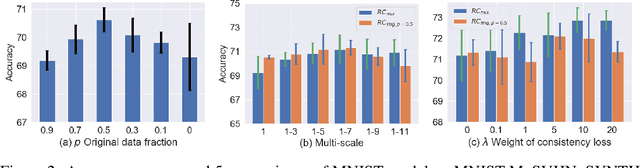
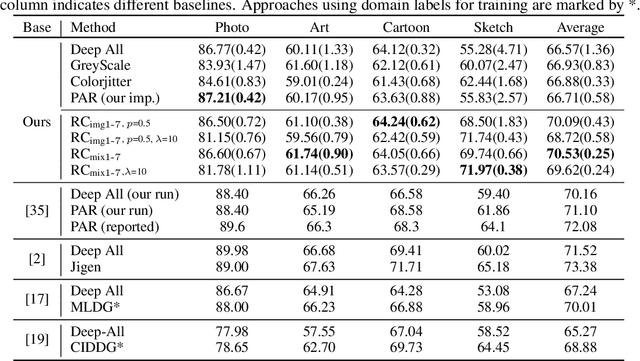
While successful for various computer vision tasks, deep neural networks have shown to be vulnerable to texture style shifts and small perturbations to which humans are robust. Hence, our goal is to train models in such a way that improves their robustness to these perturbations. We are motivated by the approximately shape-preserving property of randomized convolutions, which is due to distance preservation under random linear transforms. Intuitively, randomized convolutions create an infinite number of new domains with similar object shapes but random local texture. Therefore, we explore using outputs of multi-scale random convolutions as new images or mixing them with the original images during training. When applying a network trained with our approach to unseen domains, our method consistently improves the performance on domain generalization benchmarks and is scalable to ImageNet. Especially for the challenging scenario of generalizing to the sketch domain in PACS and to ImageNet-Sketch, our method outperforms state-of-art methods by a large margin. More interestingly, our method can benefit downstream tasks by providing a more robust pretrained visual representation.