 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAugmentation adversarial training for unsupervised speaker recognition
Paper and Code
Aug 09, 2020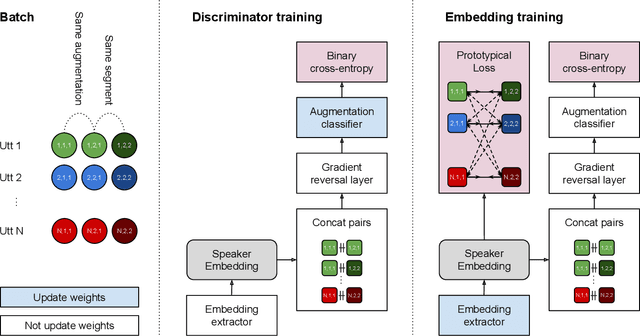
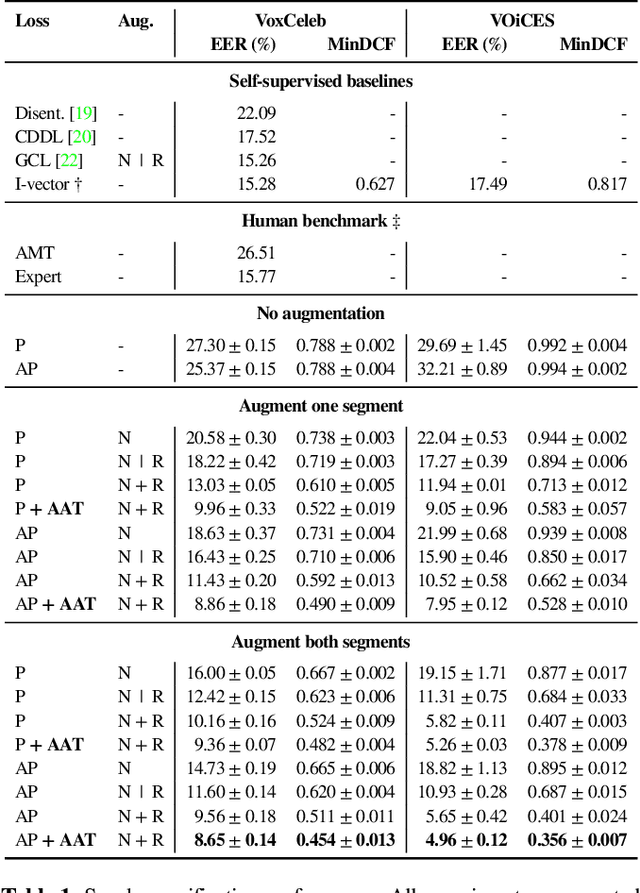
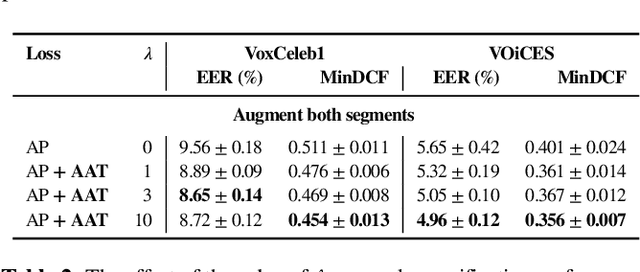
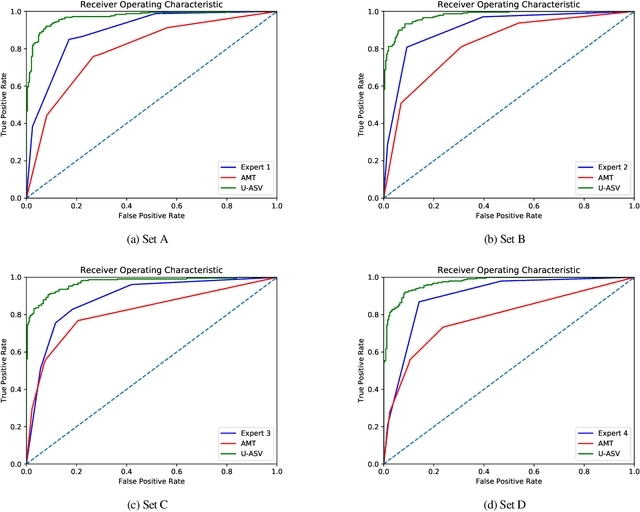
The goal of this work is to train robust speaker recognition models without speaker labels. Recent works on unsupervised speaker representations are based on contrastive learning in which they encourage within-utterance embeddings to be similar and across-utterance embeddings to be dissimilar. However, since the within-utterance segments share the same acoustic characteristics, it is difficult to separate the speaker information from the channel information. To this end, we propose augmentation adversarial training strategy that trains the network to be discriminative for the speaker information, while invariant to the augmentation applied. Since the augmentation simulates the acoustic characteristics, training the network to be invariant to augmentation also encourages the network to be invariant to the channel information in general. Extensive experiments on the VoxCeleb and VOiCES datasets show significant improvements over previous works using self-supervision, and the performance of our self-supervised models far exceed that of humans.