 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttend and Segment: Attention Guided Active Semantic Segmentation
Paper and Code
Jul 22, 2020
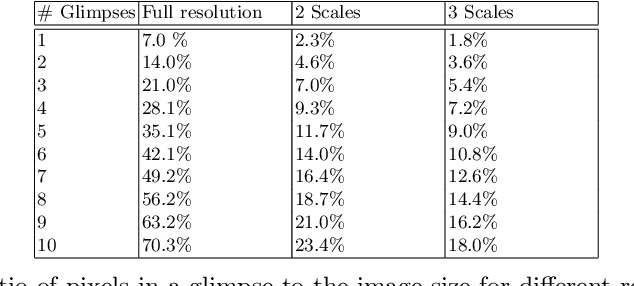
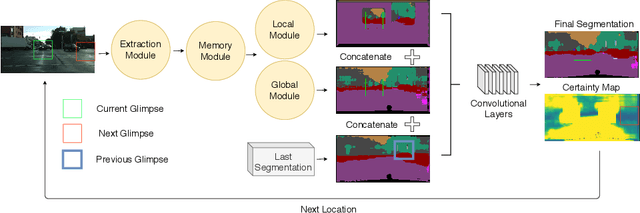
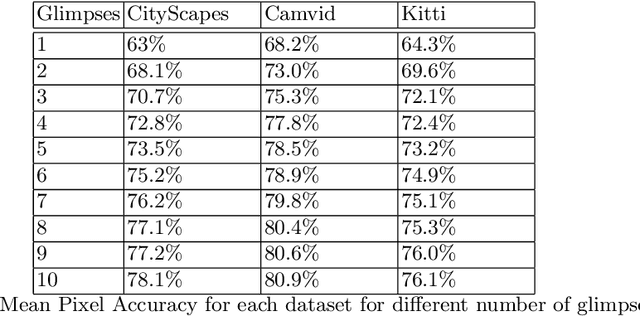
In a dynamic environment, an agent with a limited field of view/resource cannot fully observe the scene before attempting to parse it. The deployment of common semantic segmentation architectures is not feasible in such settings. In this paper we propose a method to gradually segment a scene given a sequence of partial observations. The main idea is to refine an agent's understanding of the environment by attending the areas it is most uncertain about. Our method includes a self-supervised attention mechanism and a specialized architecture to maintain and exploit spatial memory maps for filling-in the unseen areas in the environment. The agent can select and attend an area while relying on the cues coming from the visited areas to hallucinate the other parts. We reach a mean pixel-wise accuracy of 78.1%, 80.9% and 76.5% on CityScapes, CamVid, and Kitti datasets by processing only 18% of the image pixels (10 retina-like glimpses). We perform an ablation study on the number of glimpses, input image size and effectiveness of retina-like glimpses. We compare our method to several baselines and show that the optimal results are achieved by having access to a very low resolution view of the scene at the first timestep.