Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding BERT Rankers Under Distillation
Paper and Code
Jul 21, 2020
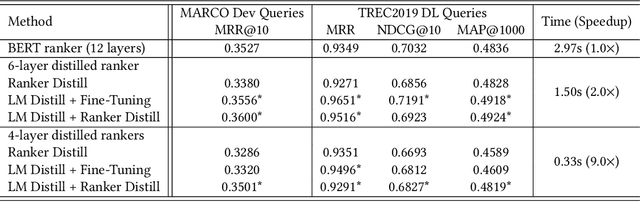
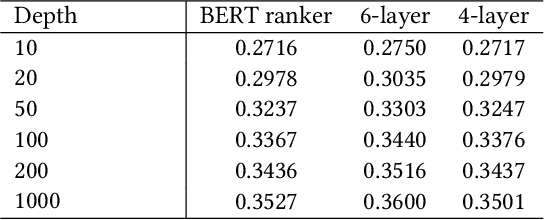
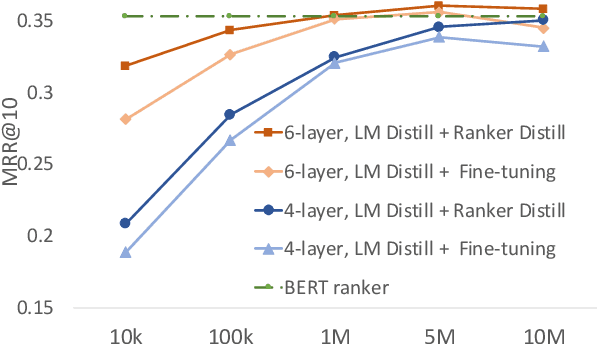
Deep language models such as BERT pre-trained on large corpus have given a huge performance boost to the state-of-the-art information retrieval ranking systems. Knowledge embedded in such models allows them to pick up complex matching signals between passages and queries. However, the high computation cost during inference limits their deployment in real-world search scenarios. In this paper, we study if and how the knowledge for search within BERT can be transferred to a smaller ranker through distillation. Our experiments demonstrate that it is crucial to use a proper distillation procedure, which produces up to nine times speedup while preserving the state-of-the-art performance.
View paper on