 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCharacter Region Attention For Text Spotting
Paper and Code
Jul 19, 2020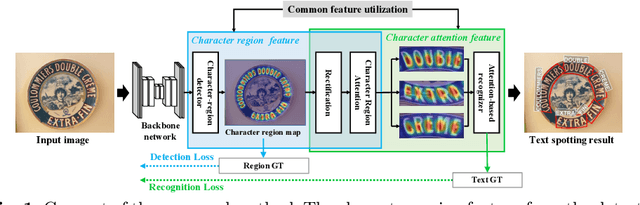
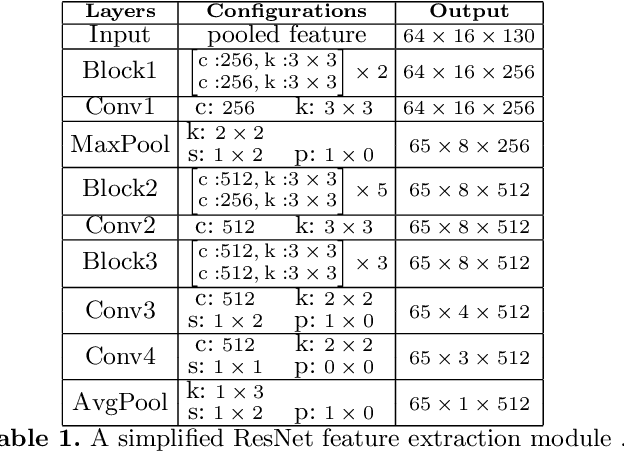
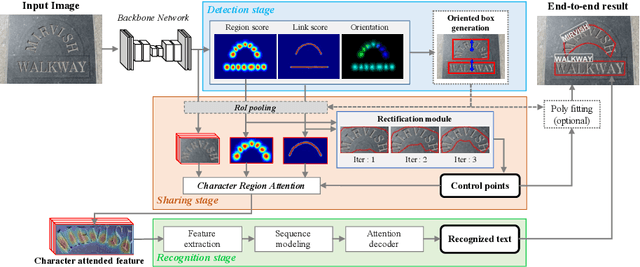
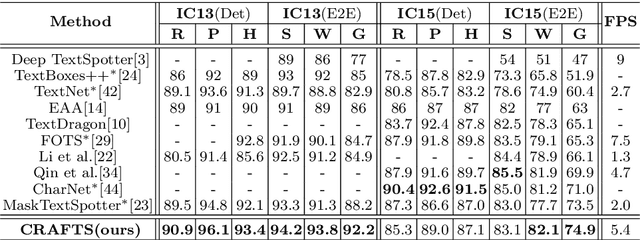
A scene text spotter is composed of text detection and recognition modules. Many studies have been conducted to unify these modules into an end-to-end trainable model to achieve better performance. A typical architecture places detection and recognition modules into separate branches, and a RoI pooling is commonly used to let the branches share a visual feature. However, there still exists a chance of establishing a more complimentary connection between the modules when adopting recognizer that uses attention-based decoder and detector that represents spatial information of the character regions. This is possible since the two modules share a common sub-task which is to find the location of the character regions. Based on the insight, we construct a tightly coupled single pipeline model. This architecture is formed by utilizing detection outputs in the recognizer and propagating the recognition loss through the detection stage. The use of character score map helps the recognizer attend better to the character center points, and the recognition loss propagation to the detector module enhances the localization of the character regions. Also, a strengthened sharing stage allows feature rectification and boundary localization of arbitrary-shaped text regions. Extensive experiments demonstrate state-of-the-art performance in publicly available straight and curved benchmark dataset.