 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Discretely Compose Reasoning Module Networks for Video Captioning
Paper and Code
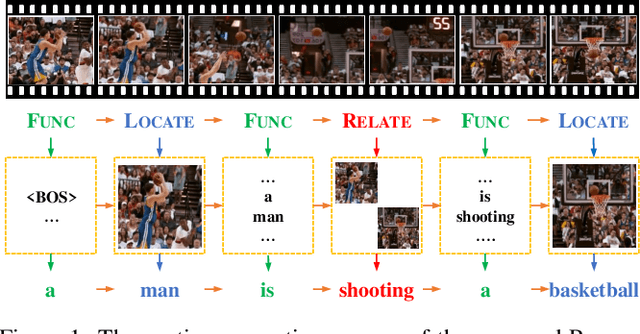

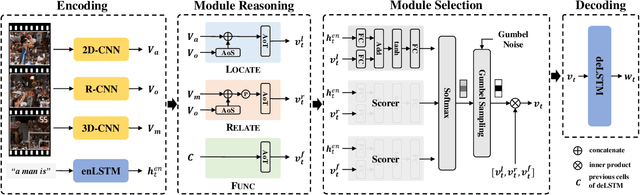
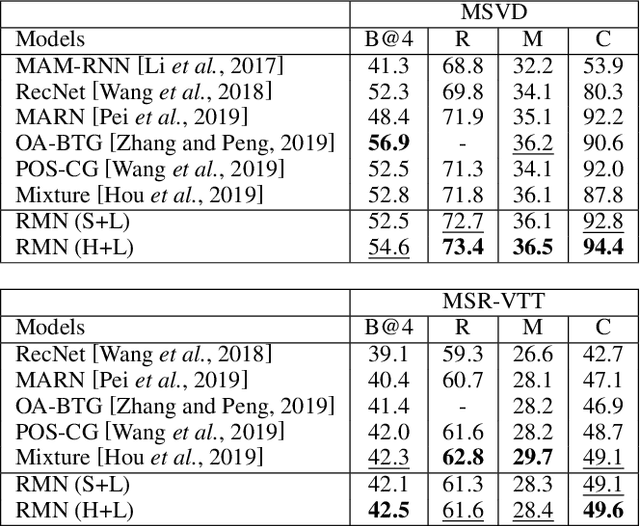
Generating natural language descriptions for videos, i.e., video captioning, essentially requires step-by-step reasoning along the generation process. For example, to generate the sentence "a man is shooting a basketball", we need to first locate and describe the subject "man", next reason out the man is "shooting", then describe the object "basketball" of shooting. However, existing visual reasoning methods designed for visual question answering are not appropriate to video captioning, for it requires more complex visual reasoning on videos over both space and time, and dynamic module composition along the generation process. In this paper, we propose a novel visual reasoning approach for video captioning, named Reasoning Module Networks (RMN), to equip the existing encoder-decoder framework with the above reasoning capacity. Specifically, our RMN employs 1) three sophisticated spatio-temporal reasoning modules, and 2) a dynamic and discrete module selector trained by a linguistic loss with a Gumbel approximation. Extensive experiments on MSVD and MSR-VTT datasets demonstrate the proposed RMN outperforms the state-of-the-art methods while providing an explicit and explainable generation process. Our code is available at https://github.com/tgc1997/RMN.