 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAudio Tagging by Cross Filtering Noisy Labels
Paper and Code
Jul 16, 2020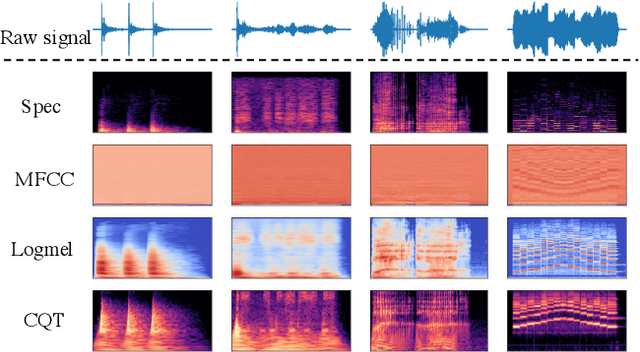
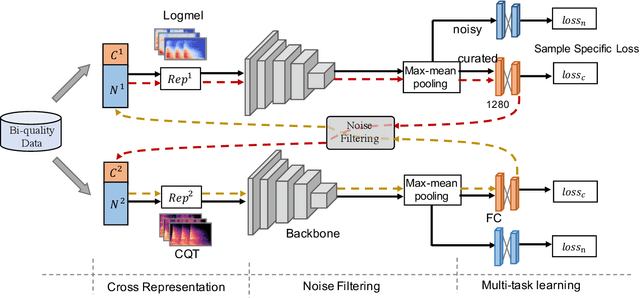
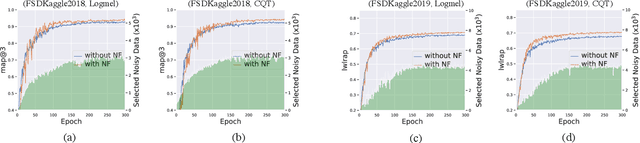
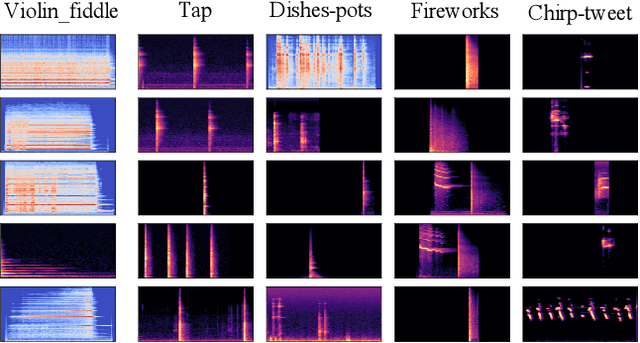
High quality labeled datasets have allowed deep learning to achieve impressive results on many sound analysis tasks. Yet, it is labor-intensive to accurately annotate large amount of audio data, and the dataset may contain noisy labels in the practical settings. Meanwhile, the deep neural networks are susceptive to those incorrect labeled data because of their outstanding memorization ability. In this paper, we present a novel framework, named CrossFilter, to combat the noisy labels problem for audio tagging. Multiple representations (such as, Logmel and MFCC) are used as the input of our framework for providing more complementary information of the audio. Then, though the cooperation and interaction of two neural networks, we divide the dataset into curated and noisy subsets by incrementally pick out the possibly correctly labeled data from the noisy data. Moreover, our approach leverages the multi-task learning on curated and noisy subsets with different loss function to fully utilize the entire dataset. The noisy-robust loss function is employed to alleviate the adverse effects of incorrect labels. On both the audio tagging datasets FSDKaggle2018 and FSDKaggle2019, empirical results demonstrate the performance improvement compared with other competing approaches. On FSDKaggle2018 dataset, our method achieves state-of-the-art performance and even surpasses the ensemble models.