 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImage Captioning with Compositional Neural Module Networks
Paper and Code
Jul 10, 2020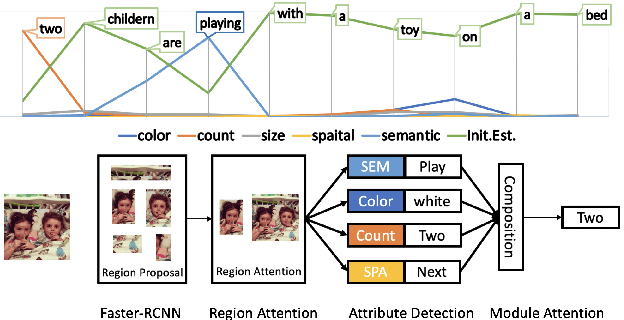
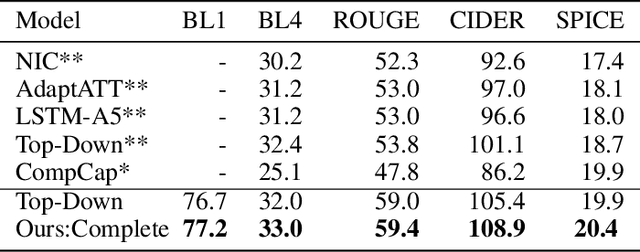
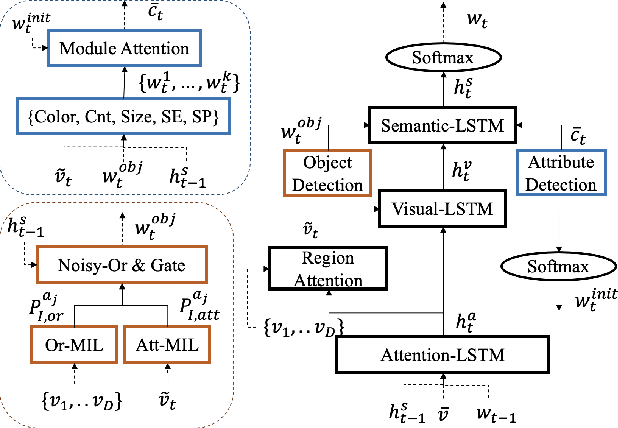

In image captioning where fluency is an important factor in evaluation, e.g., $n$-gram metrics, sequential models are commonly used; however, sequential models generally result in overgeneralized expressions that lack the details that may be present in an input image. Inspired by the idea of the compositional neural module networks in the visual question answering task, we introduce a hierarchical framework for image captioning that explores both compositionality and sequentiality of natural language. Our algorithm learns to compose a detail-rich sentence by selectively attending to different modules corresponding to unique aspects of each object detected in an input image to include specific descriptions such as counts and color. In a set of experiments on the MSCOCO dataset, the proposed model outperforms a state-of-the art model across multiple evaluation metrics, more importantly, presenting visually interpretable results. Furthermore, the breakdown of subcategories $f$-scores of the SPICE metric and human evaluation on Amazon Mechanical Turk show that our compositional module networks effectively generate accurate and detailed captions.