 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConditioned Time-Dilated Convolutions for Sound Event Detection
Paper and Code
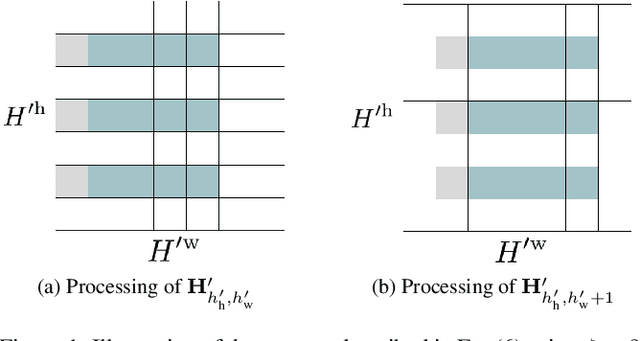
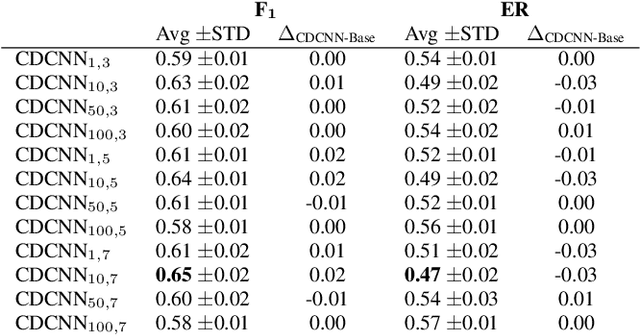
Sound event detection (SED) is the task of identifying sound events along with their onset and offset times. A recent, convolutional neural networks based SED method, proposed the usage of depthwise separable (DWS) and time-dilated convolutions. DWS and time-dilated convolutions yielded state-of-the-art results for SED, with considerable small amount of parameters. In this work we propose the expansion of the time-dilated convolutions, by conditioning them with jointly learned embeddings of the SED predictions by the SED classifier. We present a novel algorithm for the conditioning of the time-dilated convolutions which functions similarly to language modelling, and enhances the performance of the these convolutions. We employ the freely available TUT-SED Synthetic dataset, and we assess the performance of our method using the average per-frame $\text{F}_{1}$ score and average per-frame error rate, over the 10 experiments. We achieve an increase of 2\% (from 0.63 to 0.65) at the average $\text{F}_{1}$ score (the higher the better) and a decrease of 3\% (from 0.50 to 0.47) at the error rate (the lower the better).