 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDepthwise Separable Convolutions Versus Recurrent Neural Networks for Monaural Singing Voice Separation
Paper and Code

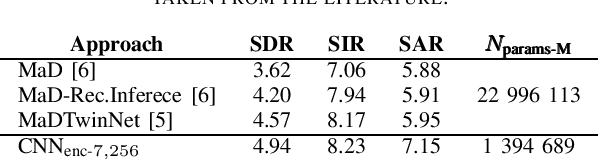
Recent approaches for music source separation are almost exclusively based on deep neural networks, mostly employing recurrent neural networks (RNNs). Although RNNs are in many cases superior than other types of deep neural networks for sequence processing, they are known to have specific difficulties in training and parallelization, especially for the typically long sequences encountered in music source separation. In this paper we present a use-case of replacing RNNs with depth-wise separable (DWS) convolutions, which are a lightweight and faster variant of the typical convolutions. We focus on singing voice separation, employing an RNN architecture, and we replace the RNNs with DWS convolutions (DWS-CNNs). We conduct an ablation study and examine the effect of the number of channels and layers of DWS-CNNs on the source separation performance, by utilizing the standard metrics of signal-to-artifacts, signal-to-interference, and signal-to-distortion ratio. Our results show that by replacing RNNs with DWS-CNNs yields an improvement of 1.20, 0.06, 0.37 dB, respectively, while using only 20.57% of the amount of parameters of the RNN architecture.