 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding and Improving Fast Adversarial Training
Paper and Code
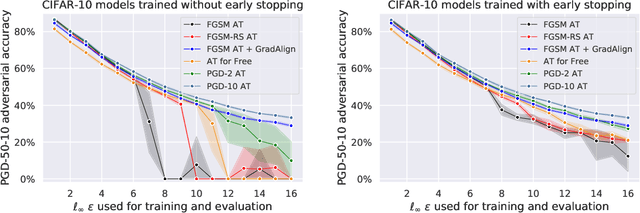

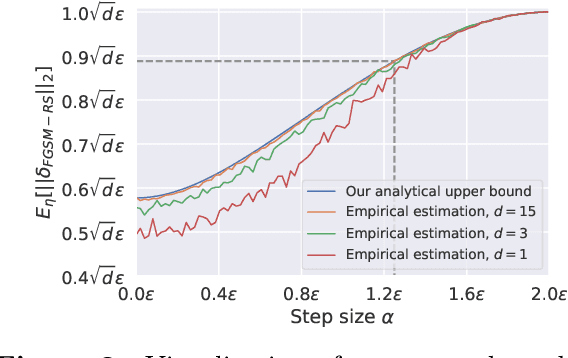
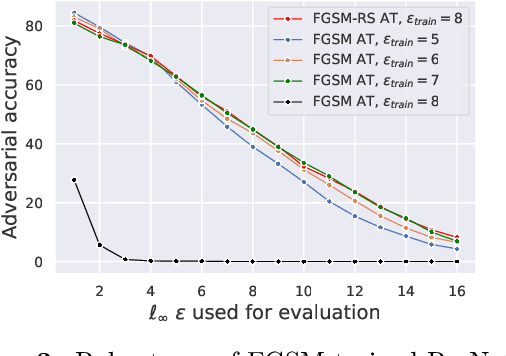
A recent line of work focused on making adversarial training computationally efficient for deep learning models. In particular, Wong et al. (2020) showed that $\ell_\infty$-adversarial training with fast gradient sign method (FGSM) can fail due to a phenomenon called "catastrophic overfitting", when the model quickly loses its robustness over a single epoch of training. We show that adding a random step to FGSM, as proposed in Wong et al. (2020), does not prevent catastrophic overfitting, and that randomness is not important per se -- its main role being simply to reduce the magnitude of the perturbation. Moreover, we show that catastrophic overfitting is not inherent to deep and overparametrized networks, but can occur in a single-layer convolutional network with a few filters. In an extreme case, even a single filter can make the network highly non-linear locally, which is the main reason why FGSM training fails. Based on this observation, we propose a new regularization method, GradAlign, that prevents catastrophic overfitting by explicitly maximizing the gradient alignment inside the perturbation set and improves the quality of the FGSM solution. As a result, GradAlign allows to successfully apply FGSM training also for larger $\ell_\infty$-perturbations and reduce the gap to multi-step adversarial training. The code of our experiments is available at https://github.com/tml-epfl/understanding-fast-adv-training.