 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAbstractive and mixed summarization for long-single documents
Paper and Code

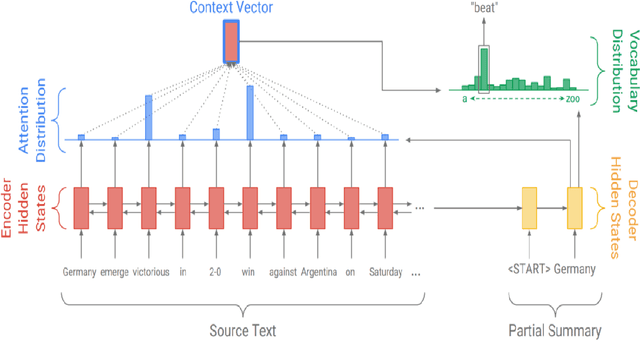
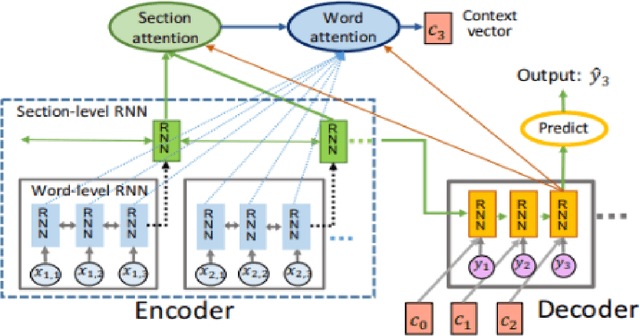
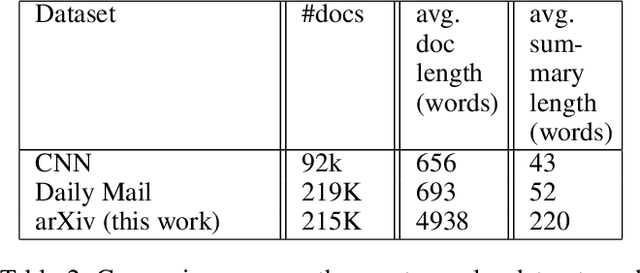
The lack of diversity in the datasets available for automatic summarization of documents has meant that the vast majority of neural models for automatic summarization have been trained with news articles. These datasets are relatively small, with an average size of about 600 words, and the models trained with such data sets see their performance limited to short documents. In order to surmount this problem, this paper uses scientific papers as the dataset on which different models are trained. These models have been chosen based on their performance on the CNN/Daily Mail data set, so that the highest ranked model of each architectural variant is selected. In this work, six different models are compared, two with an RNN architecture, one with a CNN architecture, two with a Transformer architecture and one with a Transformer architecture combined with reinforcement learning. The results from this work show that those models that use a hierarchical encoder to model the structure of the document has a better performance than the rest.