 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVerifiably Safe Exploration for End-to-End Reinforcement Learning
Paper and Code
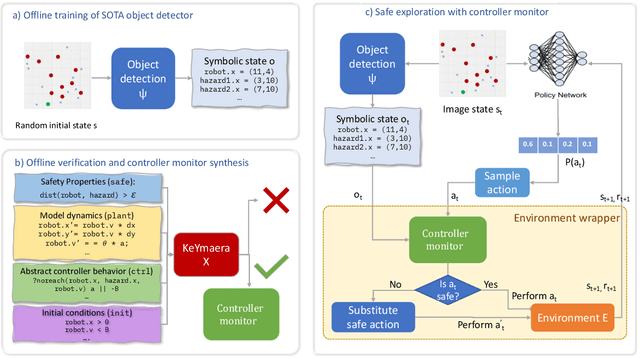
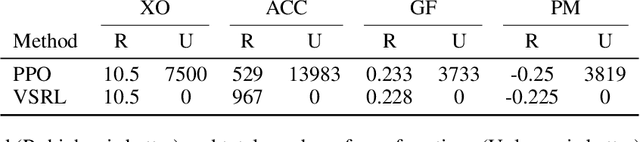
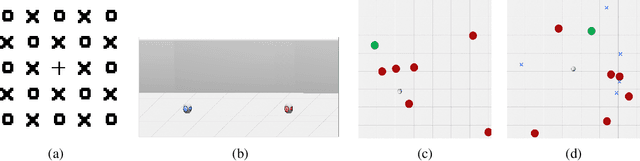

Deploying deep reinforcement learning in safety-critical settings requires developing algorithms that obey hard constraints during exploration. This paper contributes a first approach toward enforcing formal safety constraints on end-to-end policies with visual inputs. Our approach draws on recent advances in object detection and automated reasoning for hybrid dynamical systems. The approach is evaluated on a novel benchmark that emphasizes the challenge of safely exploring in the presence of hard constraints. Our benchmark draws from several proposed problem sets for safe learning and includes problems that emphasize challenges such as reward signals that are not aligned with safety constraints. On each of these benchmark problems, our algorithm completely avoids unsafe behavior while remaining competitive at optimizing for as much reward as is safe. We also prove that our method of enforcing the safety constraints preserves all safe policies from the original environment.