 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnforcing Almost-Sure Reachability in POMDPs
Paper and Code
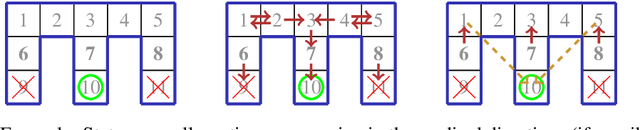
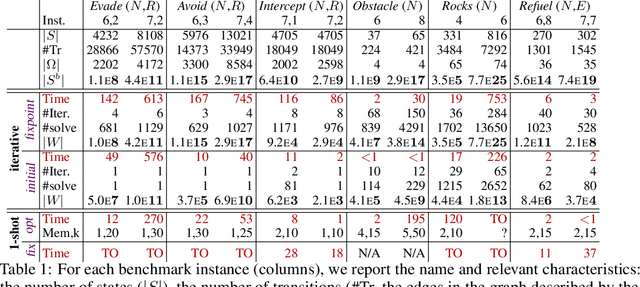

Partially-Observable Markov Decision Processes (POMDPs) are a well-known formal model for planning scenarios where agents operate under limited information about their environment. In safety-critical domains, the agent must adhere to a policy satisfying certain behavioral constraints. We study the problem of synthesizing policies that almost-surely reach some goal state while a set of bad states is never visited. In particular, we present an iterative symbolic approach that computes a winning region, that is, a set of system configurations such that all policies that stay within this set are guaranteed to satisfy the constraints. The approach generalizes and improves previous work in terms of scalability and efficacy, as demonstrated in the empirical evaluation. Additionally, we show the applicability to safe exploration by restricting agent behavior to these winning regions.