 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplainable 3D Convolutional Neural Networks by Learning Temporal Transformations
Paper and Code
Jun 29, 2020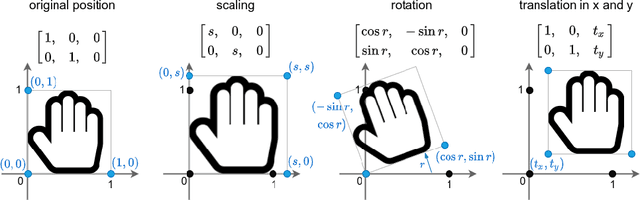


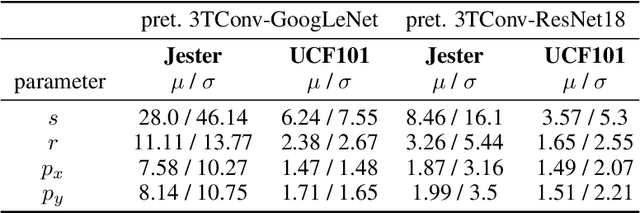
In this paper we introduce the temporally factorized 3D convolution (3TConv) as an interpretable alternative to the regular 3D convolution (3DConv). In a 3TConv the 3D convolutional filter is obtained by learning a 2D filter and a set of temporal transformation parameters, resulting in a sparse filter where the 2D slices are sequentially dependent on each other in the temporal dimension. We demonstrate that 3TConv learns temporal transformations that afford a direct interpretation. The temporal parameters can be used in combination with various existing 2D visualization methods. We also show that insight about what the model learns can be achieved by analyzing the transformation parameter statistics on a layer and model level. Finally, we implicitly demonstrate that, in popular ConvNets, the 2DConv can be replaced with a 3TConv and that the weights can be transferred to yield pretrained 3TConvs. pretrained 3TConvnets leverage more than a decade of work on traditional 2DConvNets by being able to make use of features that have been proven to deliver excellent results on image classification benchmarks.