 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrain and You'll Miss It: Interactive Model Iteration with Weak Supervision and Pre-Trained Embeddings
Paper and Code
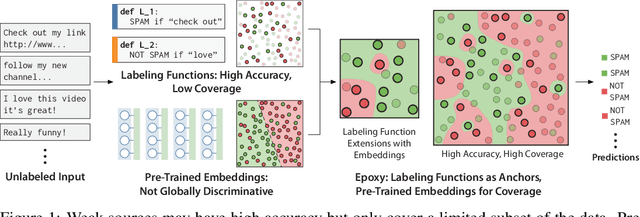
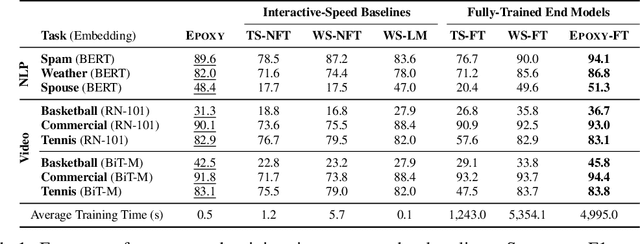
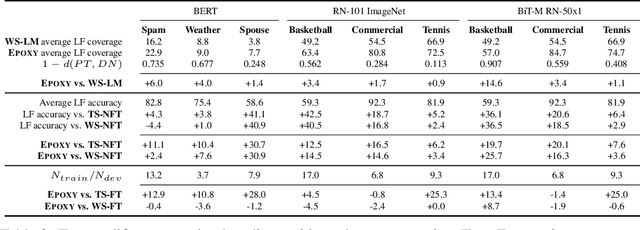
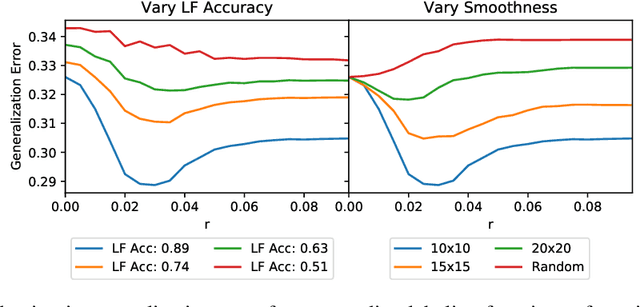
Our goal is to enable machine learning systems to be trained interactively. This requires models that perform well and train quickly, without large amounts of hand-labeled data. We take a step forward in this direction by borrowing from weak supervision (WS), wherein models can be trained with noisy sources of signal instead of hand-labeled data. But WS relies on training downstream deep networks to extrapolate to unseen data points, which can take hours or days. Pre-trained embeddings can remove this requirement. We do not use the embeddings as features as in transfer learning (TL), which requires fine-tuning for high performance, but instead use them to define a distance function on the data and extend WS source votes to nearby points. Theoretically, we provide a series of results studying how performance scales with changes in source coverage, source accuracy, and the Lipschitzness of label distributions in the embedding space, and compare this rate to standard WS without extension and TL without fine-tuning. On six benchmark NLP and video tasks, our method outperforms WS without extension by 4.1 points, TL without fine-tuning by 12.8 points, and traditionally-supervised deep networks by 13.1 points, and comes within 0.7 points of state-of-the-art weakly-supervised deep networks-all while training in less than half a second.