 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploiting Weight Redundancy in CNNs: Beyond Pruning and Quantization
Paper and Code
Jun 22, 2020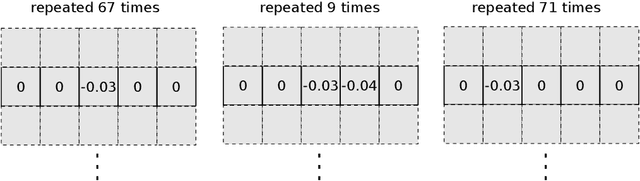
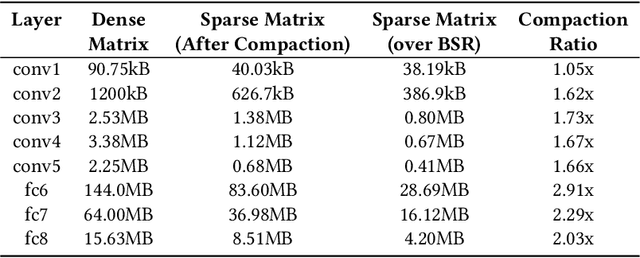
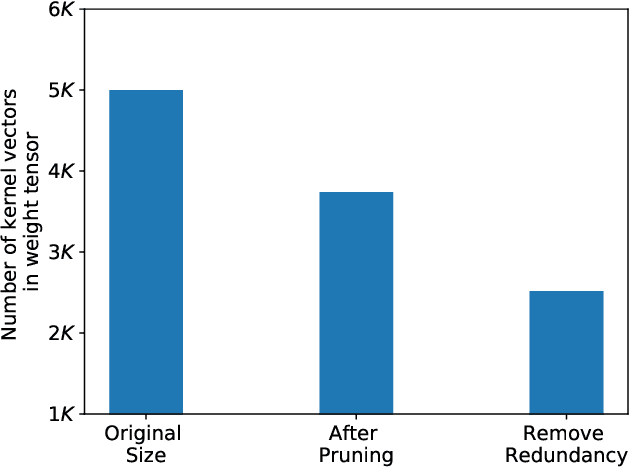
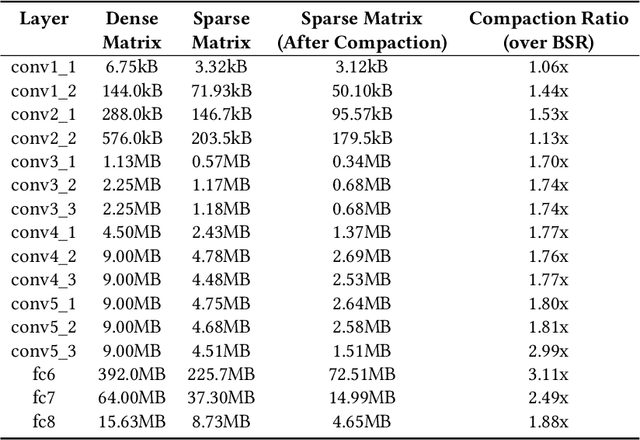
Pruning and quantization are proven methods for improving the performance and storage efficiency of convolutional neural networks (CNNs). Pruning removes near-zero weights in tensors and masks weak connections between neurons in neighbouring layers. Quantization reduces the precision of weights by replacing them with numerically similar values that require less storage. In this paper, we identify another form of redundancy in CNN weight tensors, in the form of repeated patterns of similar values. We observe that pruning and quantization both tend to drastically increase the number of repeated patterns in the weight tensors. We investigate several compression schemes to take advantage of this structure in CNN weight data, including multiple forms of Huffman coding, and other approaches inspired by block sparse matrix formats. We evaluate our approach on several well-known CNNs and find that we can achieve compaction ratios of 1.4x to 3.1x in addition to the saving from pruning and quantization.