 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn operator view of policy gradient methods
Paper and Code
Jun 22, 2020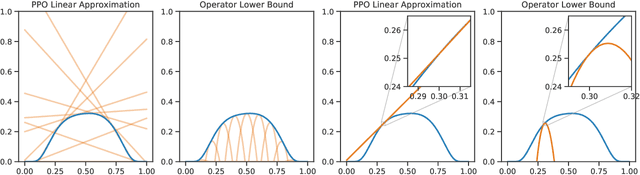
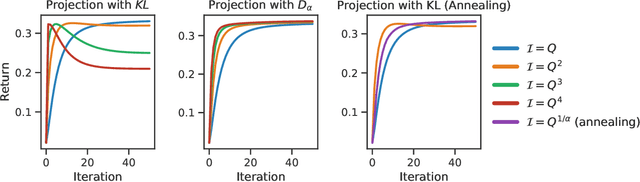
We cast policy gradient methods as the repeated application of two operators: a policy improvement operator $\mathcal{I}$, which maps any policy $\pi$ to a better one $\mathcal{I}\pi$, and a projection operator $\mathcal{P}$, which finds the best approximation of $\mathcal{I}\pi$ in the set of realizable policies. We use this framework to introduce operator-based versions of traditional policy gradient methods such as REINFORCE and PPO, which leads to a better understanding of their original counterparts. We also use the understanding we develop of the role of $\mathcal{I}$ and $\mathcal{P}$ to propose a new global lower bound of the expected return. This new perspective allows us to further bridge the gap between policy-based and value-based methods, showing how REINFORCE and the Bellman optimality operator, for example, can be seen as two sides of the same coin.