 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStochastic Bandits with Linear Constraints
Paper and Code
Jun 17, 2020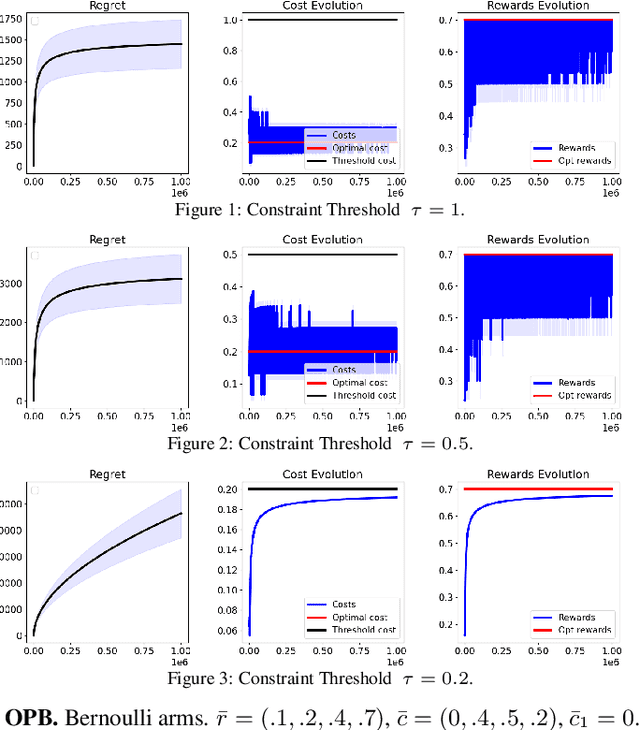
We study a constrained contextual linear bandit setting, where the goal of the agent is to produce a sequence of policies, whose expected cumulative reward over the course of $T$ rounds is maximum, and each has an expected cost below a certain threshold $\tau$. We propose an upper-confidence bound algorithm for this problem, called optimistic pessimistic linear bandit (OPLB), and prove an $\widetilde{\mathcal{O}}(\frac{d\sqrt{T}}{\tau-c_0})$ bound on its $T$-round regret, where the denominator is the difference between the constraint threshold and the cost of a known feasible action. We further specialize our results to multi-armed bandits and propose a computationally efficient algorithm for this setting. We prove a regret bound of $\widetilde{\mathcal{O}}(\frac{\sqrt{KT}}{\tau - c_0})$ for this algorithm in $K$-armed bandits, which is a $\sqrt{K}$ improvement over the regret bound we obtain by simply casting multi-armed bandits as an instance of contextual linear bandits and using the regret bound of OPLB. We also prove a lower-bound for the problem studied in the paper and provide simulations to validate our theoretical results.