 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDe-Anonymizing Text by Fingerprinting Language Generation
Paper and Code
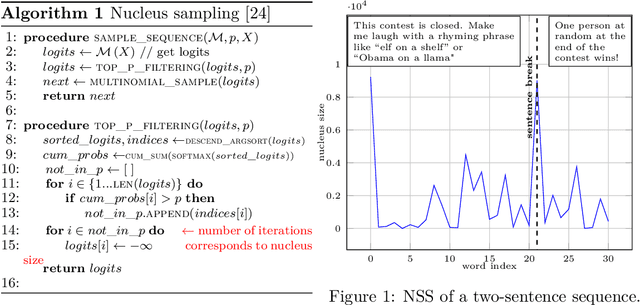
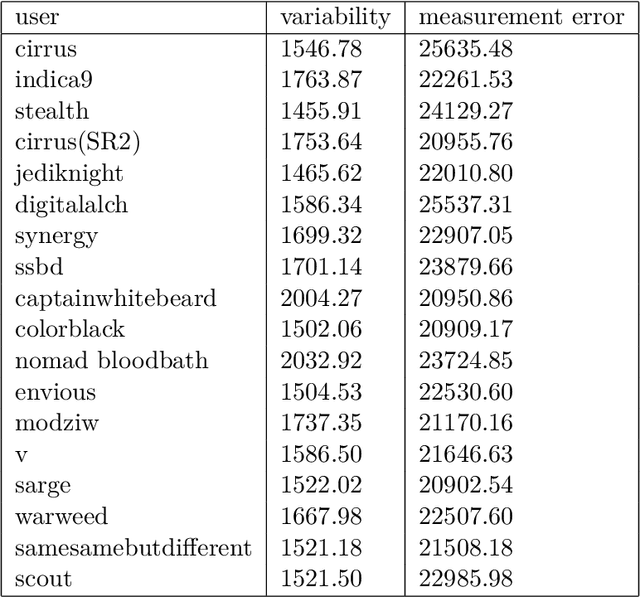
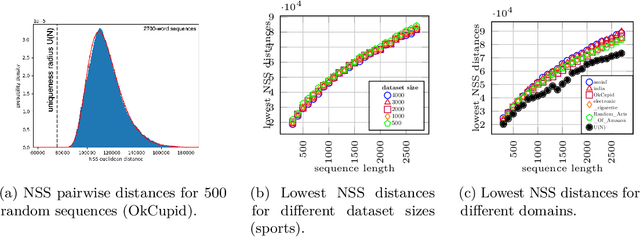
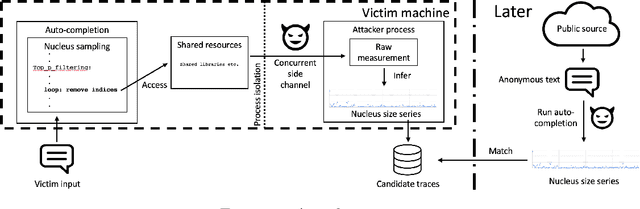
Components of machine learning systems are not (yet) perceived as security hotspots. Secure coding practices, such as ensuring that no execution paths depend on confidential inputs, have not yet been adopted by ML developers. We initiate the study of code security of ML systems by investigating how nucleus sampling---a popular approach for generating text, used for applications such as auto-completion---unwittingly leaks texts typed by users. Our main result is that the series of nucleus sizes for many natural English word sequences is a unique fingerprint. We then show how an attacker can infer typed text by measuring these fingerprints via a suitable side channel (e.g., cache access times), explain how this attack could help de-anonymize anonymous texts, and discuss defenses.