 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConvergence of Meta-Learning with Task-Specific Adaptation over Partial Parameters
Paper and Code
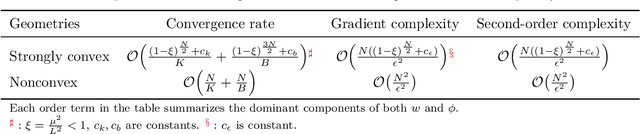
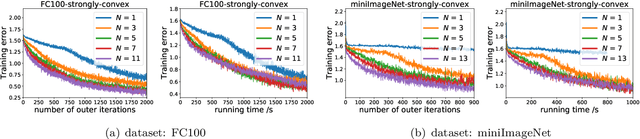
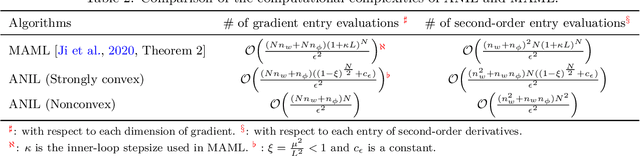
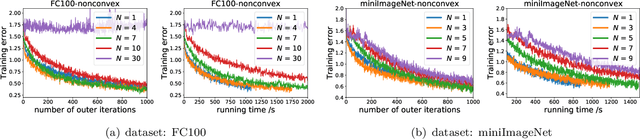
Although model-agnostic meta-learning (MAML) is a very successful algorithm in meta-learning practice, it can have high computational cost because it updates all model parameters over both the inner loop of task-specific adaptation and the outer-loop of meta initialization training. A more efficient algorithm ANIL (which refers to almost no inner loop) was proposed recently by Raghu et al. 2019, which adapts only a small subset of parameters in the inner loop and thus has substantially less computational cost than MAML as demonstrated by extensive experiments. However, the theoretical convergence of ANIL has not been studied yet. In this paper, we characterize the convergence rate and the computational complexity for ANIL under two representative inner-loop loss geometries, i.e., strongly-convexity and nonconvexity. Our results show that such a geometric property can significantly affect the overall convergence performance of ANIL. For example, ANIL achieves a faster convergence rate for a strongly-convex inner-loop loss as the number $N$ of inner-loop gradient descent steps increases, but a slower convergence rate for a nonconvex inner-loop loss as $N$ increases. Moreover, our complexity analysis provides a theoretical quantification on the improved efficiency of ANIL over MAML. The experiments on standard few-shot meta-learning benchmarks validate our theoretical findings.