 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Optimal Convergence Rate in Decentralized Stochastic Training
Paper and Code
Jun 15, 2020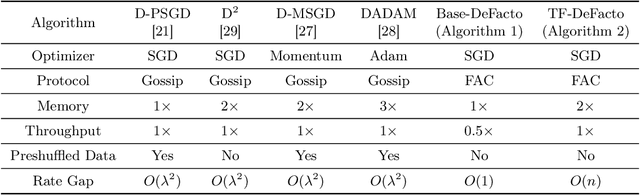
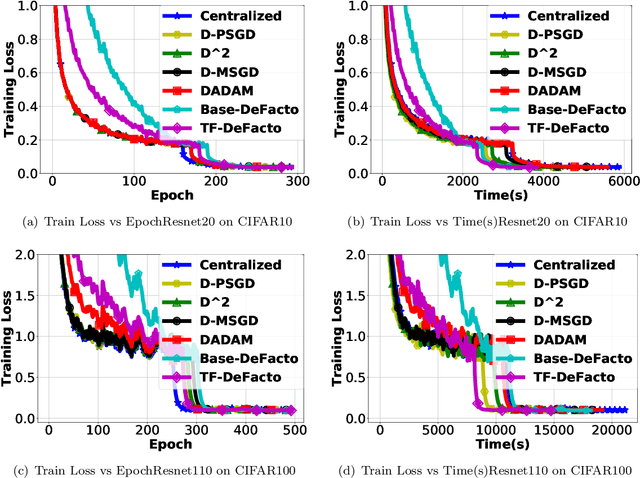
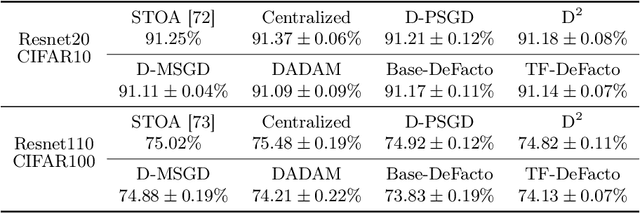

Parallel training with decentralized communication is a promising method of scaling up machine learning systems. In this paper, we provide a tight lower bound on the iteration complexity for such methods in a stochastic non-convex setting. This lower bound reveals a theoretical gap in known convergence rates of many existing algorithms. To show this bound is tight and achievable, we propose DeFacto, a class of algorithms that converge at the optimal rate without additional theoretical assumptions. We discuss the trade-offs among different algorithms regarding complexity, memory efficiency, throughput, etc. Empirically, we compare DeFacto and other decentralized algorithms via training Resnet20 on CIFAR10 and Resnet110 on CIFAR100. We show DeFacto can accelerate training with respect to wall-clock time but progresses slowly in the first few epochs.