 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Saliency Maps and Adversarial Robustness
Paper and Code
Jul 13, 2020
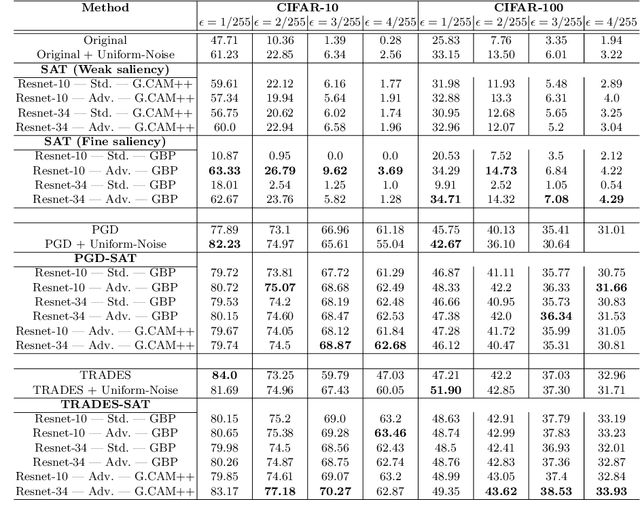
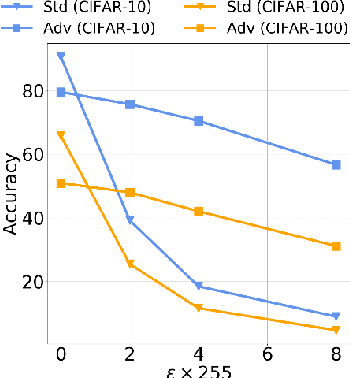
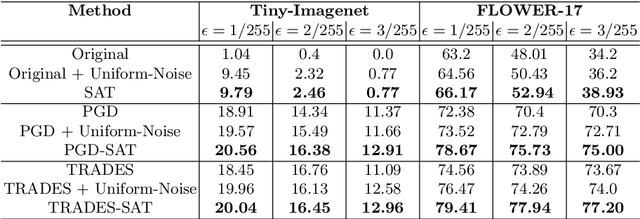
A Very recent trend has emerged to couple the notion of interpretability and adversarial robustness, unlike earlier efforts which solely focused on good interpretations or robustness against adversaries. Works have shown that adversarially trained models exhibit more interpretable saliency maps than their non-robust counterparts, and that this behavior can be quantified by considering the alignment between input image and saliency map. In this work, we provide a different perspective to this coupling, and provide a method, Saliency based Adversarial training (SAT), to use saliency maps to improve adversarial robustness of a model. In particular, we show that using annotations such as bounding boxes and segmentation masks, already provided with a dataset, as weak saliency maps, suffices to improve adversarial robustness with no additional effort to generate the perturbations themselves. Our empirical results on CIFAR-10, CIFAR-100, Tiny ImageNet and Flower-17 datasets consistently corroborate our claim, by showing improved adversarial robustness using our method. saliency maps. We also show how using finer and stronger saliency maps leads to more robust models, and how integrating SAT with existing adversarial training methods, further boosts performance of these existing methods.