 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMixMOOD: A systematic approach to class distribution mismatch in semi-supervised learning using deep dataset dissimilarity measures
Paper and Code
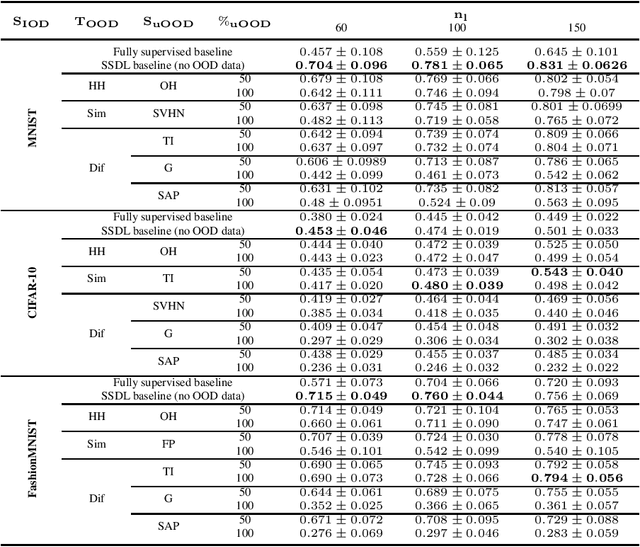
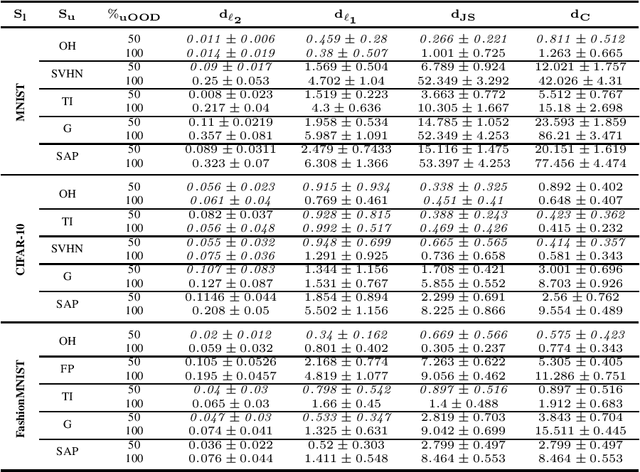
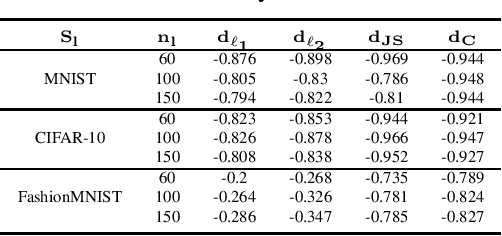
In this work, we propose MixMOOD - a systematic approach to mitigate effect of class distribution mismatch in semi-supervised deep learning (SSDL) with MixMatch. This work is divided into two components: (i) an extensive out of distribution (OOD) ablation test bed for SSDL and (ii) a quantitative unlabelled dataset selection heuristic referred to as MixMOOD. In the first part, we analyze the sensitivity of MixMatch accuracy under 90 different distribution mismatch scenarios across three multi-class classification tasks. These are designed to systematically understand how OOD unlabelled data affects MixMatch performance. In the second part, we propose an efficient and effective method, called deep dataset dissimilarity measures (DeDiMs), to compare labelled and unlabelled datasets. The proposed DeDiMs are quick to evaluate and model agnostic. They use the feature space of a generic Wide-ResNet and can be applied prior to learning. Our test results reveal that supposed semantic similarity between labelled and unlabelled data is not a good heuristic for unlabelled data selection. In contrast, strong correlation between MixMatch accuracy and the proposed DeDiMs allow us to quantitatively rank different unlabelled datasets ante hoc according to expected MixMatch accuracy. This is what we call MixMOOD. Furthermore, we argue that the MixMOOD approach can aid to standardize the evaluation of different semi-supervised learning techniques under real world scenarios involving out of distribution data.