 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBackground Modeling via Uncertainty Estimation for Weakly-supervised Action Localization
Paper and Code

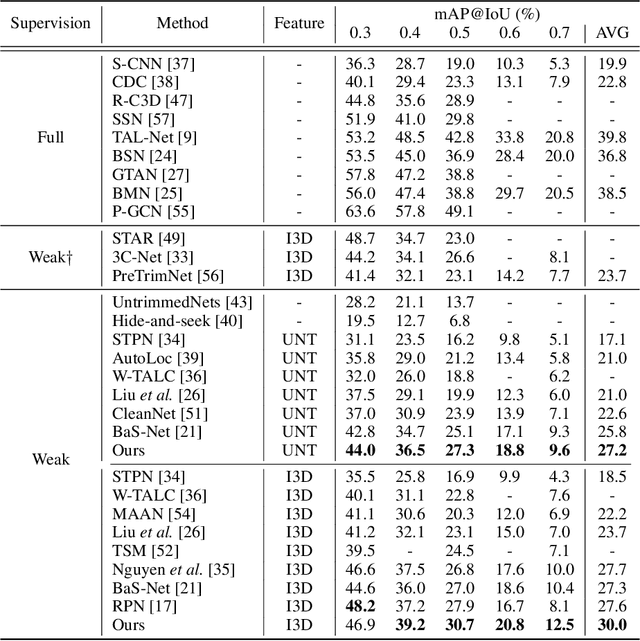
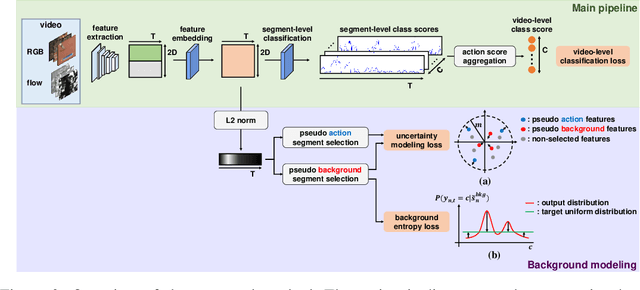
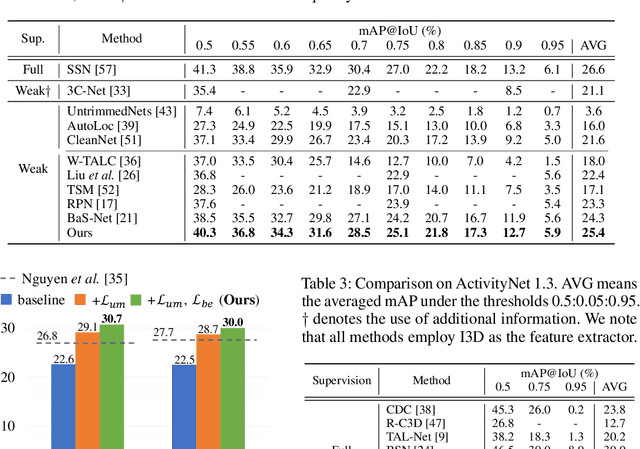
Weakly-supervised temporal action localization aims to detect intervals of action instances with only video-level action labels for training. A crucial challenge is to separate frames of action classes from remaining, denoted as background frames (i.e., frames not belonging to any action class). Previous methods attempt background modeling by either synthesizing pseudo background videos with static frames or introducing an auxiliary class for background. However, they overlook an essential fact that background frames could be dynamic and inconsistent. Accordingly, we cast the problem of identifying background frames as out-of-distribution detection and isolate it from conventional action classification. Beyond our base action localization network, we propose a module to estimate the probability of being background (i.e., uncertainty [20]), which allows us to learn uncertainty given only video-level labels via multiple instance learning. A background entropy loss is further designed to reject background frames by forcing them to have uniform probability distribution for action classes. Extensive experiments verify the effectiveness of our background modeling and show that our method significantly outperforms state-of-the-art methods on the standard benchmarks - THUMOS'14 and ActivityNet (1.2 and 1.3). Our code and the trained model are available at https://github.com/Pilhyeon/Background-Modeling-via-Uncertainty-Estimation.