 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Worst-case Regret of Linear Thompson Sampling
Paper and Code
Jun 11, 2020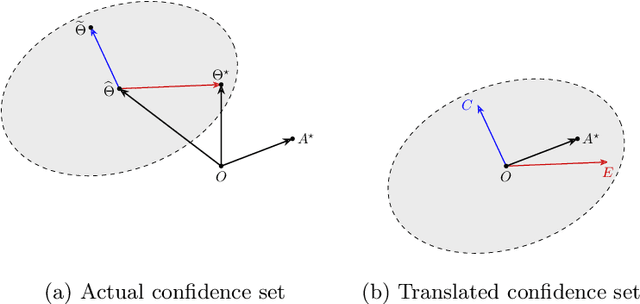
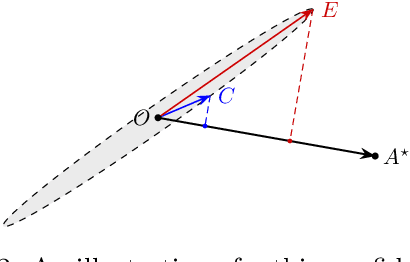
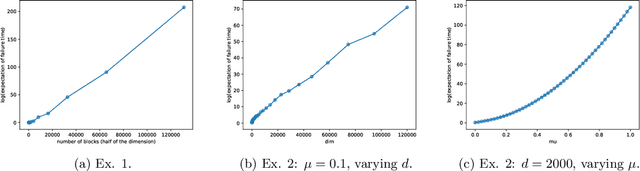
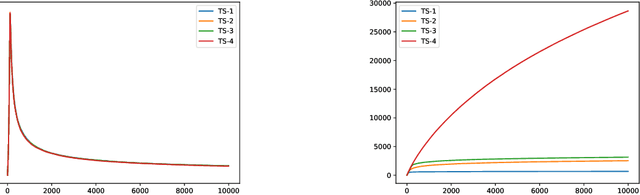
In this paper, we consider the worst-case regret of Linear Thompson Sampling (LinTS) for the linear bandit problem. Russo and Van Roy (2014) show that the Bayesian regret of LinTS is bounded above by $\widetilde{\mathcal{O}}(d\sqrt{T})$ where $T$ is the time horizon and $d$ is the number of parameters. While this bound matches the minimax lower-bounds for this problem up to logarithmic factors, the existence of a similar worst-case regret bound is still unknown. The only known worst-case regret bound for LinTS, due to Agrawal and Goyal (2013b); Abeille et al. (2017), is $\widetilde{\mathcal{O}}(d\sqrt{dT})$ which requires the posterior variance to be inflated by a factor of $\widetilde{\mathcal{O}}(\sqrt{d})$. While this bound is far from the minimax optimal rate by a factor of $\sqrt{d}$, in this paper we show that it is the best possible one can get, settling an open problem stated in Russo et al. (2018). Specifically, we construct examples to show that, without the inflation, LinTS can incur linear regret up to time $\exp(\mathcal{O}(d))$. We then demonstrate that, under mild conditions, a slightly modified version of LinTS requires only an $\widetilde{\mathcal{O}}(1)$ inflation where the constant depends on the diversity of the optimal arm.