 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Optimal Weighted $\ell_2$ Regularization in Overparameterized Linear Regression
Paper and Code
Jun 25, 2020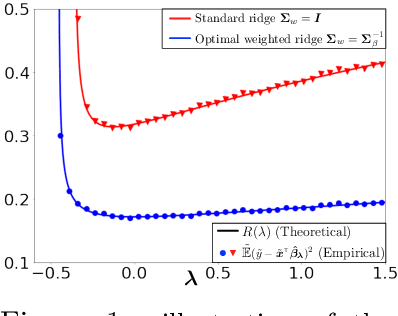
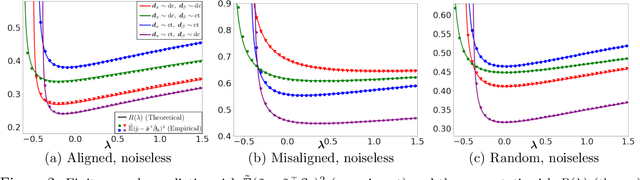
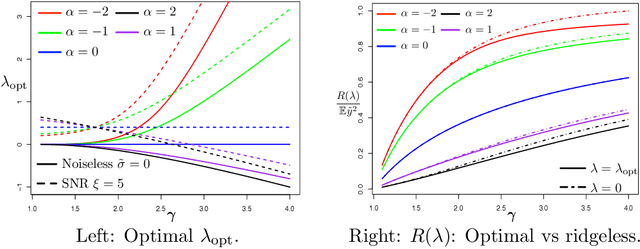
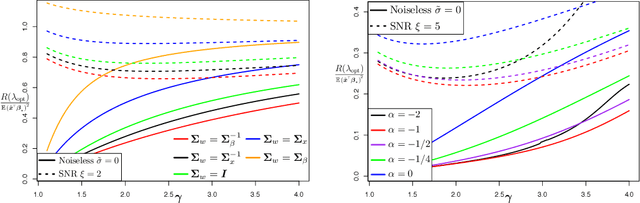
We consider the linear model $\mathbf{y} = \mathbf{X} \mathbf{\beta}_\star + \mathbf{\epsilon}$ with $\mathbf{X}\in \mathbb{R}^{n\times p}$ in the overparameterized regime $p>n$. We estimate $\mathbf{\beta}_\star$ via generalized (weighted) ridge regression: $\hat{\mathbf{\beta}}_\lambda = \left(\mathbf{X}^T\mathbf{X} + \lambda \mathbf{\Sigma}_w\right)^\dagger \mathbf{X}^T\mathbf{y}$, where $\mathbf{\Sigma}_w$ is the weighting matrix. Assuming a random effects model with general data covariance $\mathbf{\Sigma}_x$ and anisotropic prior on the true coefficients $\mathbf{\beta}_\star$, i.e., $\mathbb{E}\mathbf{\beta}_\star\mathbf{\beta}_\star^T = \mathbf{\Sigma}_\beta$, we provide an exact characterization of the prediction risk $\mathbb{E}(y-\mathbf{x}^T\hat{\mathbf{\beta}}_\lambda)^2$ in the proportional asymptotic limit $p/n\rightarrow \gamma \in (1,\infty)$. Our general setup leads to a number of interesting findings. We outline precise conditions that decide the sign of the optimal setting $\lambda_{\rm opt}$ for the ridge parameter $\lambda$ and confirm the implicit $\ell_2$ regularization effect of overparameterization, which theoretically justifies the surprising empirical observation that $\lambda_{\rm opt}$ can be negative in the overparameterized regime. We also characterize the double descent phenomenon for principal component regression (PCR) when $\mathbf{X}$ and $\mathbf{\beta}_\star$ are non-isotropic. Finally, we determine the optimal $\mathbf{\Sigma}_w$ for both the ridgeless ($\lambda\to 0$) and optimally regularized ($\lambda = \lambda_{\rm opt}$) case, and demonstrate the advantage of the weighted objective over standard ridge regression and PCR.