 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePicket: Self-supervised Data Diagnostics for ML Pipelines
Paper and Code
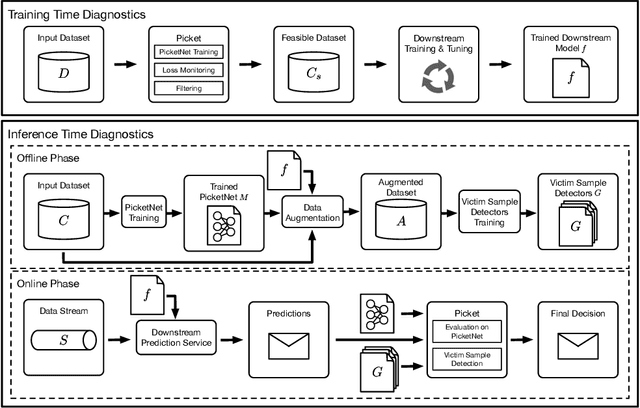
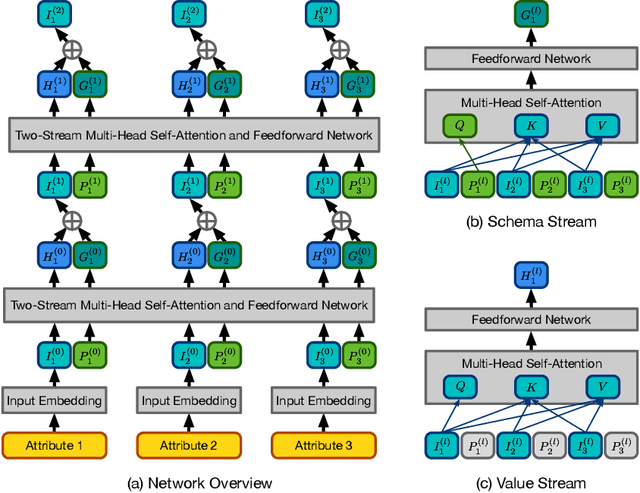
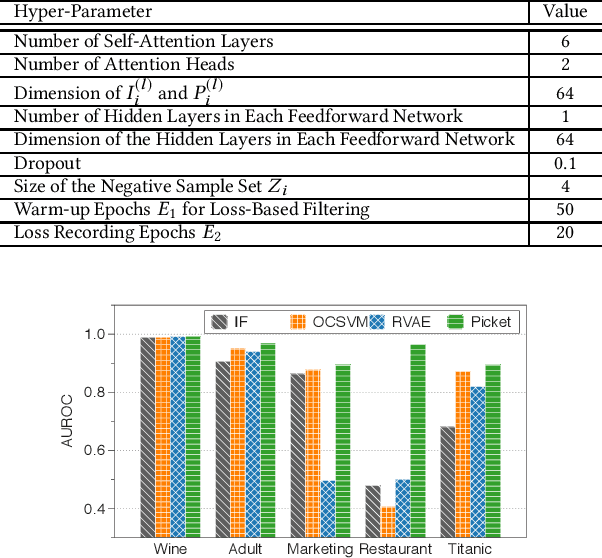
Data corruption is an impediment to modern machine learning deployments. Corrupted data can severely bias the learned model and can also lead to invalid inference. We present, Picket, a first-of-its-kind system that enables data diagnostics for machine learning pipelines over tabular data. Picket can safeguard against data corruptions that lead to degradation either during training or deployment. For the training stage, Picket identifies erroneous training examples that can result in a biased model, while for the deployment stage, Picket flags corrupted query points to a trained machine learning model that due to noise will result to incorrect predictions. Picket is built around a novel self-supervised deep learning model for mixed-type tabular data. Learning this model is fully unsupervised to minimize the burden of deployment, and Picket is designed as a plugin that can increase the robustness of any machine learning pipeline. We evaluate Picket on a diverse array of real-world data considering different corruption models that include systematic and adversarial noise. We show that Picket offers consistently accurate diagnostics during both training and deployment of various models ranging from SVMs to neural networks, beating competing methods of data quality validation in machine learning pipelines.