 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChromatic Learning for Sparse Datasets
Paper and Code
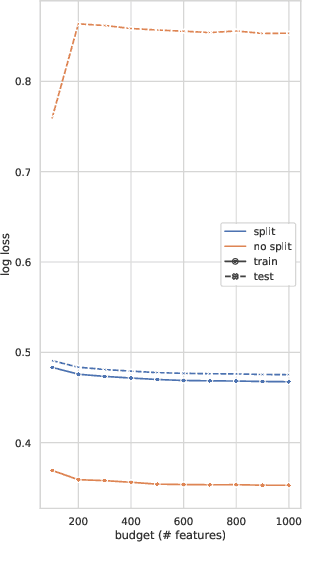
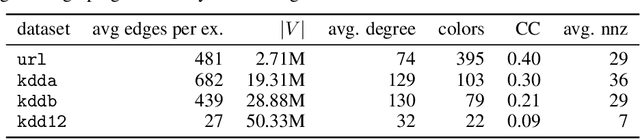
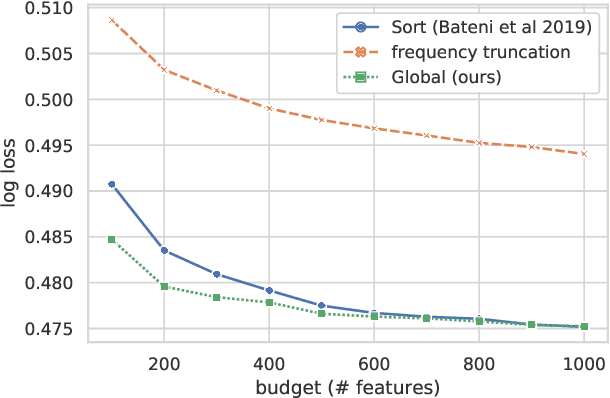
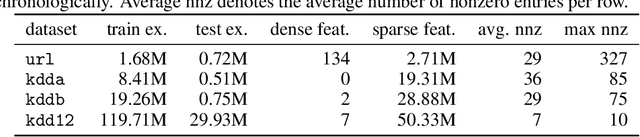
Learning over sparse, high-dimensional data frequently necessitates the use of specialized methods such as the hashing trick. In this work, we design a highly scalable alternative approach that leverages the low degree of feature co-occurrences present in many practical settings. This approach, which we call Chromatic Learning (CL), obtains a low-dimensional dense feature representation by performing graph coloring over the co-occurrence graph of features---an approach previously used as a runtime performance optimization for GBDT training. This color-based dense representation can be combined with additional dense categorical encoding approaches, e.g., submodular feature compression, to further reduce dimensionality. CL exhibits linear parallelizability and consumes memory linear in the size of the co-occurrence graph. By leveraging the structural properties of the co-occurrence graph, CL can compress sparse datasets, such as KDD Cup 2012, that contain over 50M features down to 1024, using an order of magnitude fewer features than frequency-based truncation and the hashing trick while maintaining the same test error for linear models. This compression further enables the use of deep networks in this wide, sparse setting, where CL similarly has favorable performance compared to existing baselines for budgeted input dimension.