 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTriple descent and the two kinds of overfitting: Where & why do they appear?
Paper and Code
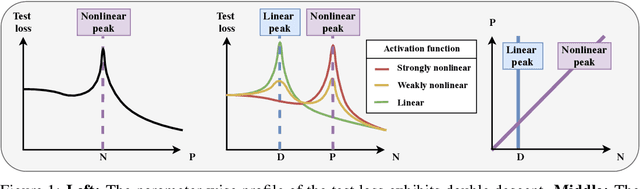
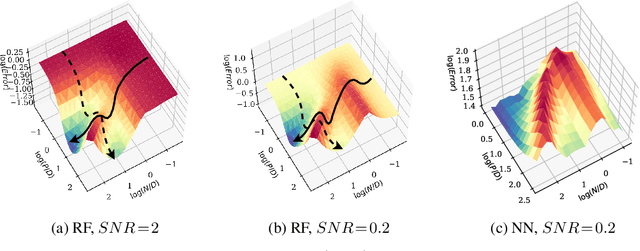
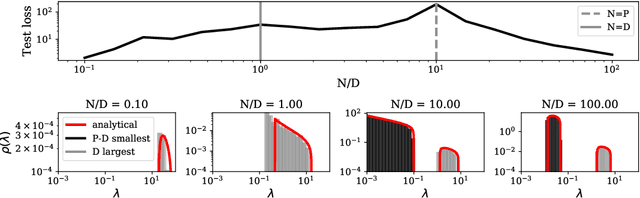
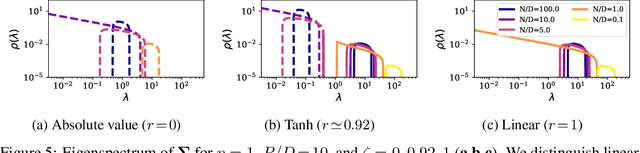
A recent line of research has highlighted the existence of a double descent phenomenon in deep learning, whereby increasing the number of training examples $N$ causes the generalization error of neural networks to peak when $N$ is of the same order as the number of parameters $P$. In earlier works, a similar phenomenon was shown to exist in simpler models such as linear regression, where the peak instead occurs when $N$ is equal to the input dimension $D$. In both cases, the location of the peak coincides with the interpolation threshold. In this paper, we show that despite their apparent similarity, these two scenarios are inherently different. In fact, both peaks can co-exist when neural networks are applied to noisy regression tasks. The relative size of the peaks is governed by the degree of nonlinearity of the activation function. Building on recent developments in the analysis of random feature models, we provide a theoretical ground for this sample-wise triple descent. As shown previously, the nonlinear peak at $N\!=\!P$ is a true divergence caused by the extreme sensitivity of the output function to both the noise corrupting the labels and the initialization of the random features (or the weights in neural networks). This peak survives in the absence of noise, but can be suppressed by regularization. In contrast, the linear peak at $N\!=\!D$ is solely due to overfitting the noise in the labels, and forms earlier during training. We show that this peak is implicitly regularized by the nonlinearity, which is why it only becomes salient at high noise and is weakly affected by explicit regularization. Throughout the paper, we compare the analytical results obtained in the random feature model with the outcomes of numerical experiments involving realistic neural networks.