 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Neural Light Transport
Paper and Code
Jun 05, 2020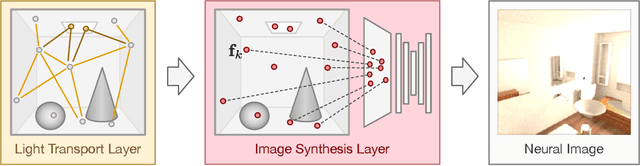
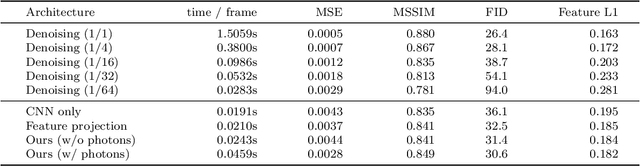
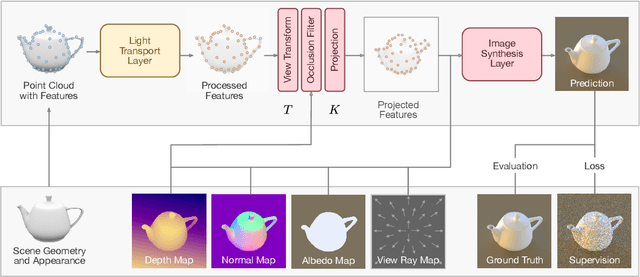
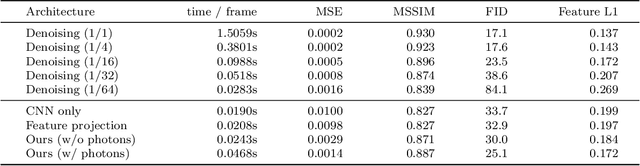
In recent years, deep generative models have gained significance due to their ability to synthesize natural-looking images with applications ranging from virtual reality to data augmentation for training computer vision models. While existing models are able to faithfully learn the image distribution of the training set, they often lack controllability as they operate in 2D pixel space and do not model the physical image formation process. In this work, we investigate the importance of 3D reasoning for photorealistic rendering. We present an approach for learning light transport in static and dynamic 3D scenes using a neural network with the goal of predicting photorealistic images. In contrast to existing approaches that operate in the 2D image domain, our approach reasons in both 3D and 2D space, thus enabling global illumination effects and manipulation of 3D scene geometry. Experimentally, we find that our model is able to produce photorealistic renderings of static and dynamic scenes. Moreover, it compares favorably to baselines which combine path tracing and image denoising at the same computational budget.