 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePick-Object-Attack: Type-Specific Adversarial Attack for Object Detection
Paper and Code

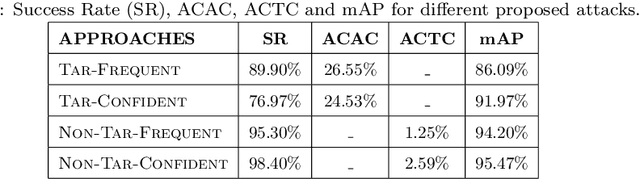
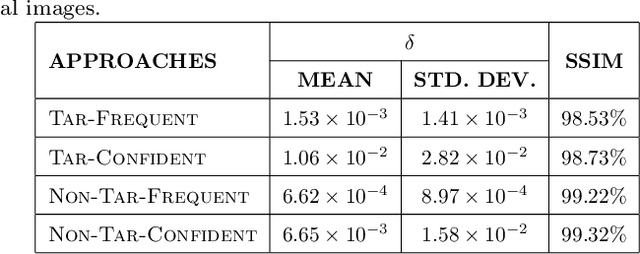
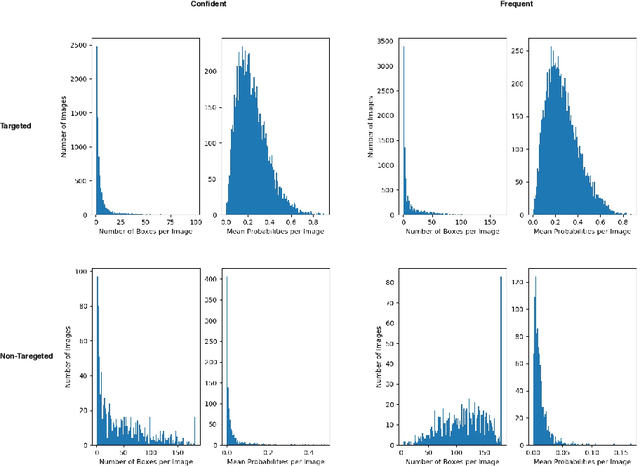
Many recent studies have shown that deep neural models are vulnerable to adversarial samples: images with imperceptible perturbations, for example, can fool image classifiers. In this paper, we generate adversarial examples for object detection, which entails detecting bounding boxes around multiple objects present in the image and classifying them at the same time, making it a harder task than against image classification. We specifically aim to attack the widely used Faster R-CNN by changing the predicted label for a particular object in an image: where prior work has targeted one specific object (a stop sign), we generalise to arbitrary objects, with the key challenge being the need to change the labels of all bounding boxes for all instances of that object type. To do so, we propose a novel method, named Pick-Object-Attack. Pick-Object-Attack successfully adds perturbations only to bounding boxes for the targeted object, preserving the labels of other detected objects in the image. In terms of perceptibility, the perturbations induced by the method are very small. Furthermore, for the first time, we examine the effect of adversarial attacks on object detection in terms of a downstream task, image captioning; we show that where a method that can modify all object types leads to very obvious changes in captions, the changes from our constrained attack are much less apparent.