 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Optimal Transport for Robust Multi-View Learning
Paper and Code
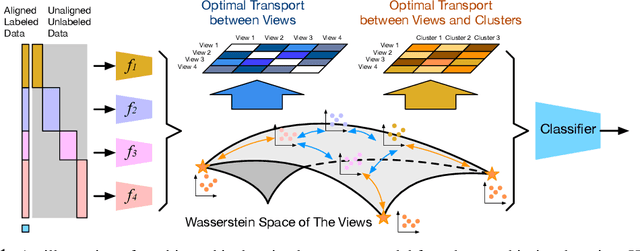

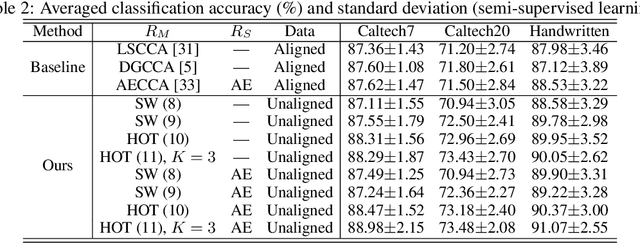
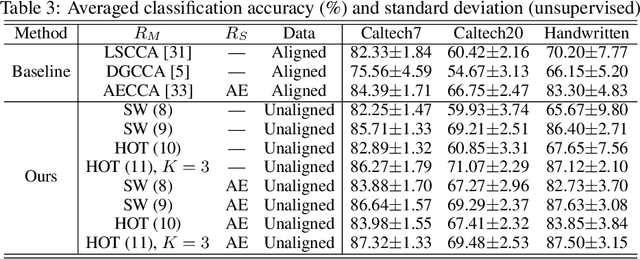
Traditional multi-view learning methods often rely on two assumptions: ($i$) the samples in different views are well-aligned, and ($ii$) their representations in latent space obey the same distribution. Unfortunately, these two assumptions may be questionable in practice, which limits the application of multi-view learning. In this work, we propose a hierarchical optimal transport (HOT) method to mitigate the dependency on these two assumptions. Given unaligned multi-view data, the HOT method penalizes the sliced Wasserstein distance between the distributions of different views. These sliced Wasserstein distances are used as the ground distance to calculate the entropic optimal transport across different views, which explicitly indicates the clustering structure of the views. The HOT method is applicable to both unsupervised and semi-supervised learning, and experimental results show that it performs robustly on both synthetic and real-world tasks.