 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProblem-Complexity Adaptive Model Selection for Stochastic Linear Bandits
Paper and Code
Jun 15, 2020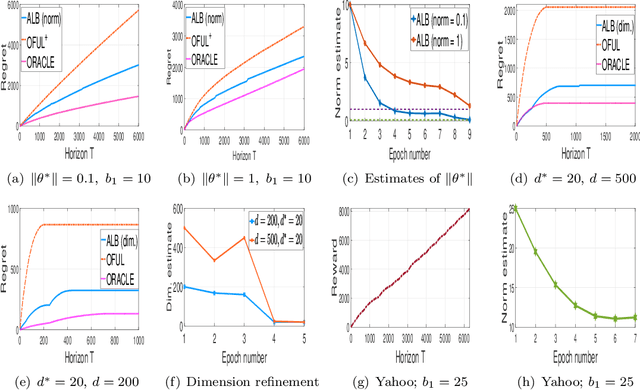
We consider the problem of model selection for two popular stochastic linear bandit settings, and propose algorithms that adapts to the unknown problem complexity. In the first setting, we consider the $K$ armed mixture bandits, where the mean reward of arm $i \in [K]$, is $\mu_i+ \langle \alpha_{i,t},\theta^* \rangle $, with $\alpha_{i,t} \in \mathbb{R}^d$ being the known context vector and $\mu_i \in [-1,1]$ and $\theta^*$ are unknown parameters. We define $\|\theta^*\|$ as the problem complexity and consider a sequence of nested hypothesis classes, each positing a different upper bound on $\|\theta^*\|$. Exploiting this, we propose Adaptive Linear Bandit (ALB), a novel phase based algorithm that adapts to the true problem complexity, $\|\theta^*\|$. We show that ALB achieves regret scaling of $O(\|\theta^*\|\sqrt{T})$, where $\|\theta^*\|$ is apriori unknown. As a corollary, when $\theta^*=0$, ALB recovers the minimax regret for the simple bandit algorithm without such knowledge of $\theta^*$. ALB is the first algorithm that uses parameter norm as model section criteria for linear bandits. Prior state of art algorithms \cite{osom} achieve a regret of $O(L\sqrt{T})$, where $L$ is the upper bound on $\|\theta^*\|$, fed as an input to the problem. In the second setting, we consider the standard linear bandit problem (with possibly an infinite number of arms) where the sparsity of $\theta^*$, denoted by $d^* \leq d$, is unknown to the algorithm. Defining $d^*$ as the problem complexity, we show that ALB achieves $O(d^*\sqrt{T})$ regret, matching that of an oracle who knew the true sparsity level. This methodology is then extended to the case of finitely many arms and similar results are proven. This is the first algorithm that achieves such model selection guarantees. We further verify our results via synthetic and real-data experiments.