 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Effects of Mild Over-parameterization on the Optimization Landscape of Shallow ReLU Neural Networks
Paper and Code
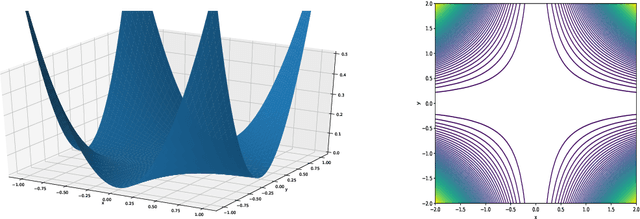
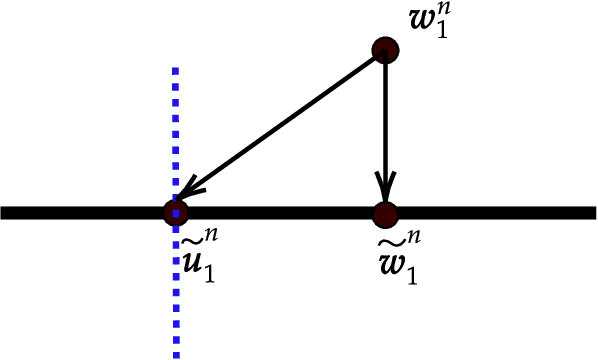
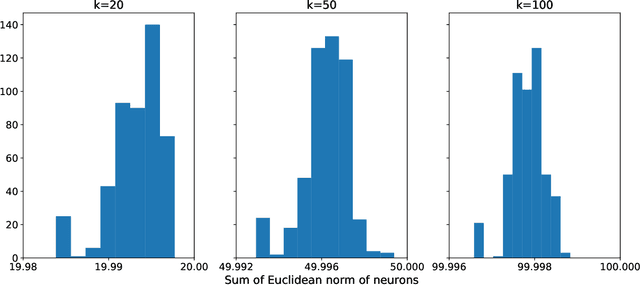
We study the effects of mild over-parameterization on the optimization landscape of a simple ReLU neural network of the form $\mathbf{x}\mapsto\sum_{i=1}^k\max\{0,\mathbf{w}_i^{\top}\mathbf{x}\}$, in a well-studied teacher-student setting where the target values are generated by the same architecture, and when directly optimizing over the population squared loss with respect to Gaussian inputs. We prove that while the objective is strongly convex around the global minima when the teacher and student networks possess the same number of neurons, it is not even \emph{locally convex} after any amount of over-parameterization. Moreover, related desirable properties (e.g., one-point strong convexity and the Polyak-{\L}ojasiewicz condition) also do not hold even locally. On the other hand, we establish that the objective remains one-point strongly convex in \emph{most} directions (suitably defined). For the non-global minima, we prove that adding even just a single neuron will turn a non-global minimum into a saddle point. This holds under some technical conditions which we validate empirically. These results provide a possible explanation for why recovering a global minimum becomes significantly easier when we over-parameterize, even if the amount of over-parameterization is very moderate.