 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgnostic Learning of a Single Neuron with Gradient Descent
Paper and Code
Jun 11, 2020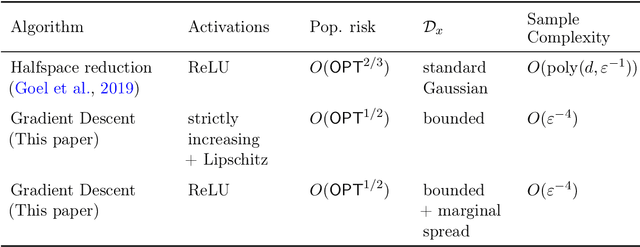
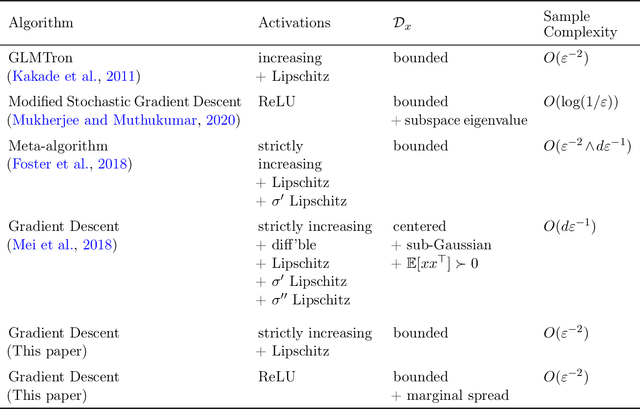
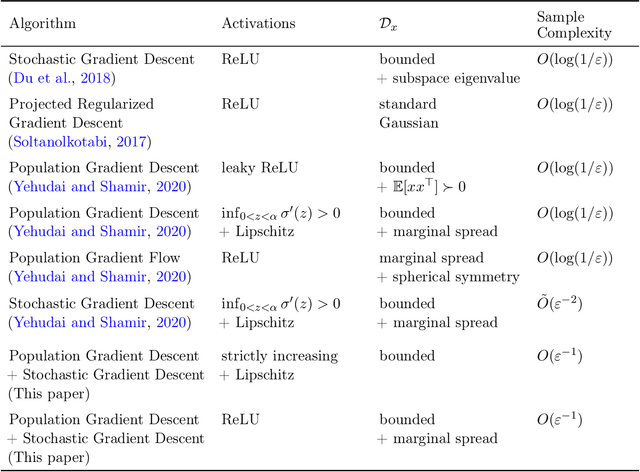
We consider the problem of learning the best-fitting single neuron as measured by the expected square loss $\mathbb{E}_{(x,y)\sim \mathcal{D}}[(\sigma(w^\top x)-y)^2]$ over some unknown joint distribution $\mathcal{D}$ by using gradient descent to minimize the empirical risk induced by a set of i.i.d. samples $S\sim \mathcal{D}^n$. The activation function $\sigma$ is an arbitrary Lipschitz and non-decreasing function, making the optimization problem nonconvex and nonsmooth in general, and covers typical neural network activation functions and inverse link functions in the generalized linear model setting. In the agnostic PAC learning setting, where no assumption on the relationship between the labels $y$ and the input $x$ is made, if the optimal population risk is $\mathsf{OPT}$, we show that gradient descent achieves population risk $O(\mathsf{OPT}^{1/2})+\epsilon$ in polynomial time and sample complexity. When labels take the form $y = \sigma(v^\top x) + \xi$ for zero-mean sub-Gaussian noise $\xi$, we show that gradient descent achieves population risk $\mathsf{OPT} + \epsilon$. Our sample complexity and runtime guarantees are (almost) dimension independent, and when $\sigma$ is strictly increasing and Lipschitz, require no distributional assumptions beyond boundedness. For ReLU, we show the same results under a nondegeneracy assumption for the marginal distribution of the input. To the best of our knowledge, this is the first result for agnostic learning of a single neuron using gradient descent.