 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Can Self-Attention Be Replaced by Feed Forward Layers?
Paper and Code
May 28, 2020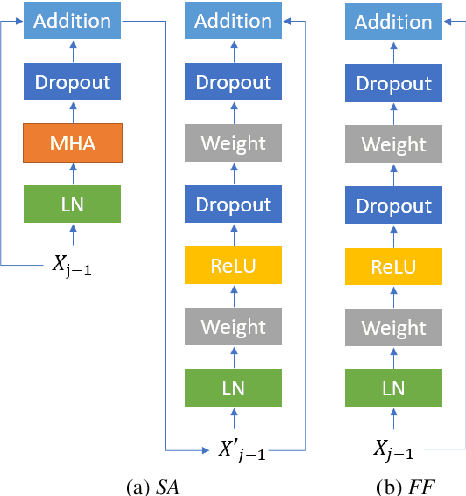
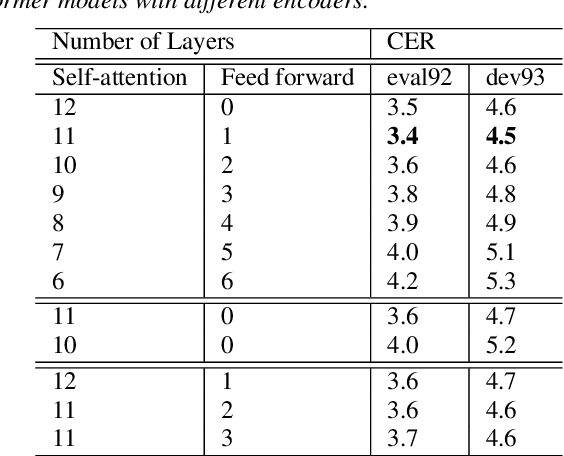

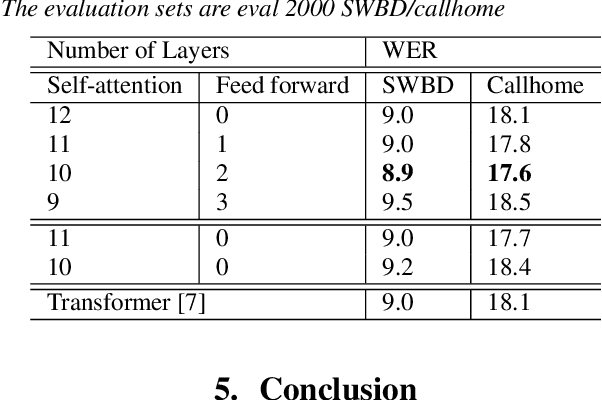
Recently, self-attention models such as Transformers have given competitive results compared to recurrent neural network systems in speech recognition. The key factor for the outstanding performance of self-attention models is their ability to capture temporal relationships without being limited by the distance between two related events. However, we note that the range of the learned context progressively increases from the lower to upper self-attention layers, whilst acoustic events often happen within short time spans in a left-to-right order. This leads to a question: for speech recognition, is a global view of the entire sequence still important for the upper self-attention layers in the encoder of Transformers? To investigate this, we replace these self-attention layers with feed forward layers. In our speech recognition experiments (Wall Street Journal and Switchboard), we indeed observe an interesting result: replacing the upper self-attention layers in the encoder with feed forward layers leads to no performance drop, and even minor gains. Our experiments offer insights to how self-attention layers process the speech signal, leading to the conclusion that the lower self-attention layers of the encoder encode a sufficiently wide range of inputs, hence learning further contextual information in the upper layers is unnecessary.