 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeS3VAE: Self-Supervised Sequential VAE for Representation Disentanglement and Data Generation
Paper and Code
May 23, 2020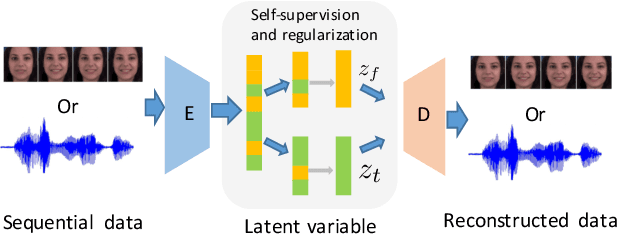

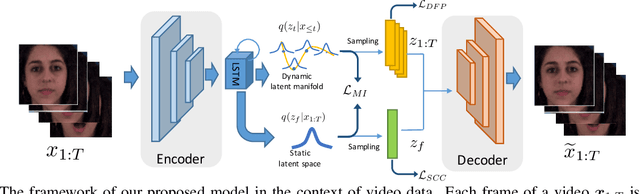
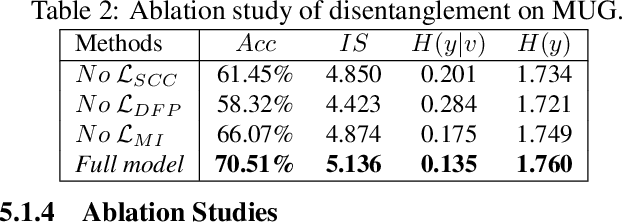
We propose a sequential variational autoencoder to learn disentangled representations of sequential data (e.g., videos and audios) under self-supervision. Specifically, we exploit the benefits of some readily accessible supervisory signals from input data itself or some off-the-shelf functional models and accordingly design auxiliary tasks for our model to utilize these signals. With the supervision of the signals, our model can easily disentangle the representation of an input sequence into static factors and dynamic factors (i.e., time-invariant and time-varying parts). Comprehensive experiments across videos and audios verify the effectiveness of our model on representation disentanglement and generation of sequential data, and demonstrate that, our model with self-supervision performs comparable to, if not better than, the fully-supervised model with ground truth labels, and outperforms state-of-the-art unsupervised models by a large margin.