 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoint Detection and Tracking in Videos with Identification Features
Paper and Code
May 25, 2020
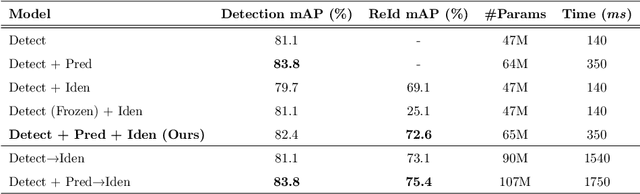
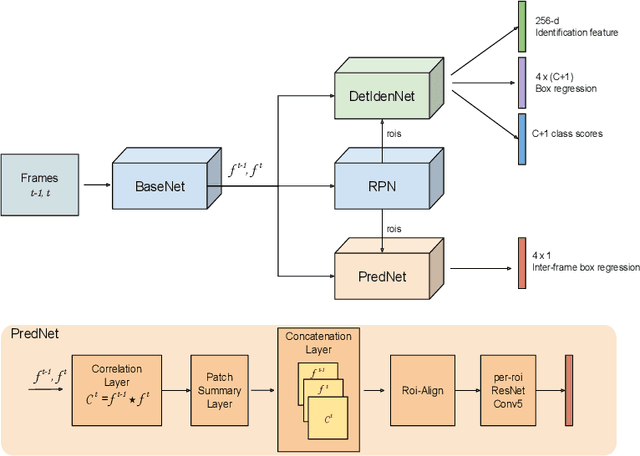
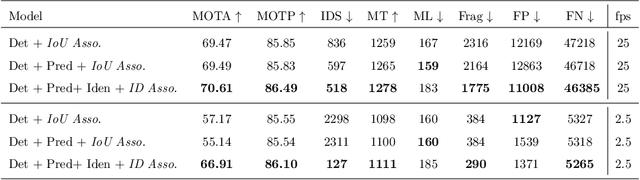
Recent works have shown that combining object detection and tracking tasks, in the case of video data, results in higher performance for both tasks, but they require a high frame-rate as a strict requirement for performance. This is assumption is often violated in real-world applications, when models run on embedded devices, often at only a few frames per second. Videos at low frame-rate suffer from large object displacements. Here re-identification features may support to match large-displaced object detections, but current joint detection and re-identification formulations degrade the detector performance, as these two are contrasting tasks. In the real-world application having separate detector and re-id models is often not feasible, as both the memory and runtime effectively double. Towards robust long-term tracking applicable to reduced-computational-power devices, we propose the first joint optimization of detection, tracking and re-identification features for videos. Notably, our joint optimization maintains the detector performance, a typical multi-task challenge. At inference time, we leverage detections for tracking (tracking-by-detection) when the objects are visible, detectable and slowly moving in the image. We leverage instead re-identification features to match objects which disappeared (e.g. due to occlusion) for several frames or were not tracked due to fast motion (or low-frame-rate videos). Our proposed method reaches the state-of-the-art on MOT, it ranks 1st in the UA-DETRAC'18 tracking challenge among online trackers, and 3rd overall.